




At the same time, it is also often used when obtaining data from IoT sensors. Because of this, it is necessary to look at the issue of how to get data from it. What is an effective method, and how to avoid some possible problems?
As always, I’ll take it one step at a time. So let’s start with what JSON is and what its structure is.
JSON + Structure
JSON stands for JavaScript Object Notation. Or for a language that works for recording and JavaScript objects. It is a language that allows us to create semi-structured files where data is assigned to named fields. JSON is flexible and can accept anything as long as the basic structure is followed. It also supports that two records do not have to have the same name fields. One can have more / less than the other. At the same time, they may not have anything in common, and the record may even be empty. At the same time, a number can appear within the same name field and sometimes text or even some more complex structure. Because of this, working with JSON files can sometimes be quite unpleasant. It may or may not!
Regarding the structure, JSON essentially distinguishes two primary objects:
- Array - defined by: []
- Object-defined by: {}
Both of these objects can be passed empty. But, at the same time, they can be combined arbitrarily, and thanks to this, a very complex structure can be created, which can be multi-dimensional from a certain point of view.
An example of what the JSON looks like:
{
"p": [
{"id":1},
{"id":2,"name":"AAA"}
],
"status": 200
}Example of a JSON file starting as Array:
[
{"id":1},
{"id":2,"name":"AAA"}
]The text is classically stored within quotation marks, defining the name fields within the records. The numbers are, of course, without quotation marks.
Power BI and JSON
If you start working with a JSON file within Power BI, notice that Power Query will use the Json.Document() function when initially loading this file. This will allow him to read the file and convert it into a similar concept of List and Records, which we know well in Power Query. It flips the bracket system exactly. [] become {} and vice versa. Why? Because Power Query declares RECORD objects with [] and LIST with {}, so the same concept as JSON.
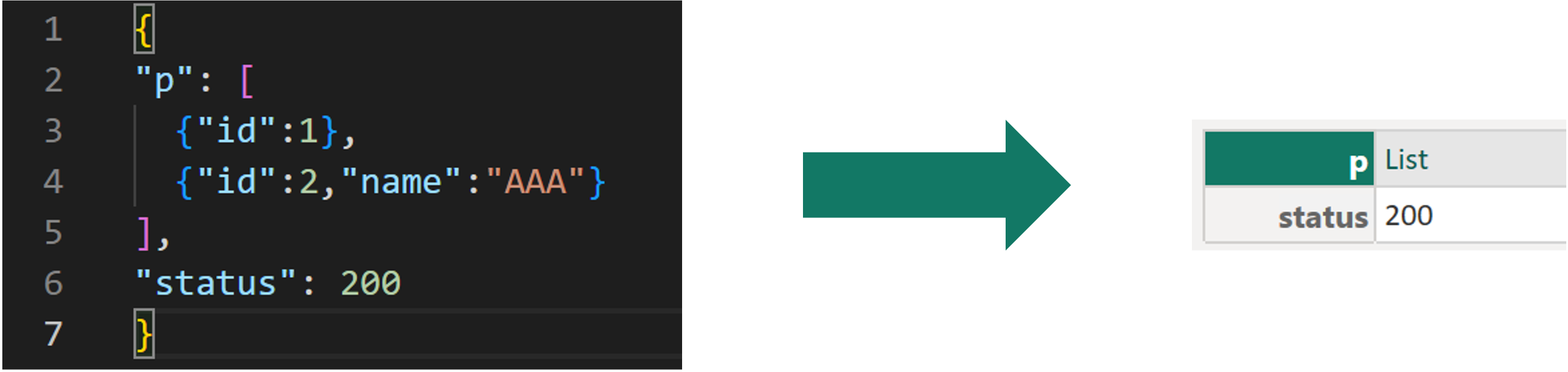 JSON converted by Power Query
JSON converted by Power Query
Of course, if the JSON file itself already starts as an Array, then Power Query will convert it to a List of Records. This gives us direct options to start extracting data.
Extracting
As we mentioned, we have many options for extracting this data. And it’s good to map them out a bit. The most well-known variant is through the UI, when we choose a list with the data we need and then convert the list to a table and then obtain individual values from the resulting column with records:
 Converting List to Table
Converting List to Table
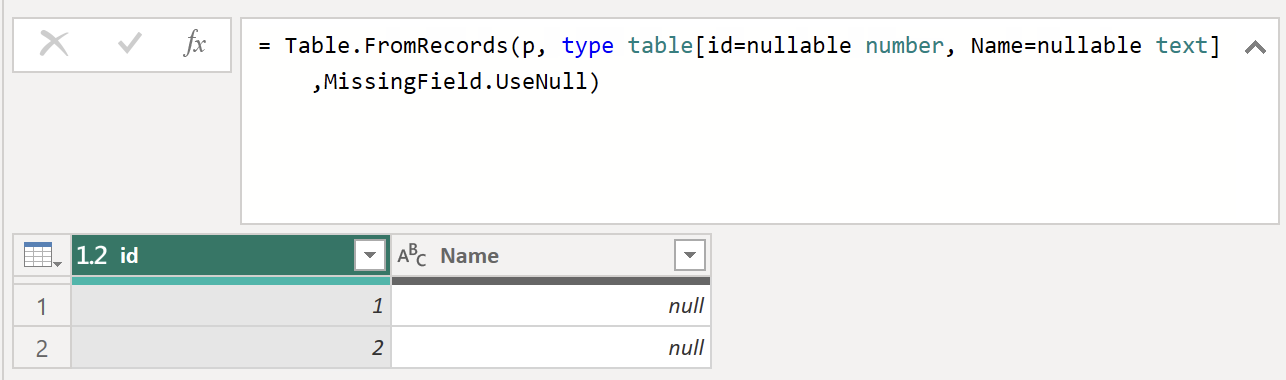
Although this method is available to every user without intervening in the code, it also contains an unnecessary step. Specifically, the step that converts the List to a table. Suppose we intervened in the code and replaced the previous procedure with the Table.FromRecords() function, which requires a list of records from which the Table will be created, we would save one step.
 List of Records convereted to Table
List of Records convereted to Table
This example shows that this method has at least one problem. This means the first record specifies the columns, so you will only read them dynamically if all columns are in the first record. This can be avoided by manually defining the columns within this function.
Table.FromRecords(p, type table [id = nullable number, name = nullable text], MissingField.UseNull)Unfortunately, within the function, you need to say how to behave explicitly in case of missing columns, so add the MissingField.UseNull parameter. At the same time, for it to work correctly, it is necessary to set the data type to nullable in advance for all columns. However, if a namespace is identified within the record that needs to define in advance, it will be ignored again. In the same way, if the name of the column defined by us does not match the name within the record, for example, because of a capital letter at the beginning of the word, it will also be ignored.
 Wrong name of column
Wrong name of column
At the same time, this method means that if we wanted to rename one of the extracted columns, we would not do it directly within the table creation process. Instead, we would have to do that in the next step.
At that moment, however, it already smells like we could reach for another offered method: the #table initiator. This is because it requires two input parameters—one for defining the columns and the other for the rows.
#table(columns as any, rows as any) as anyHere we can define individual columns, including their data types, within the columns, similar to what we did a while ago. But we still have to add some lines to it. One of the most straightforward variants is through a list of lists, where the values within the nested sheet will be sequentially reached into individual columns. But before we jump into defining these values and their order, it should be mentioned that the #table requires us to always pass EXACTLY THE SAME number of values as the required columns. So we have to make sure that we always return at least an empty null value.
We can use the List.Transform() function for this transformation, when we turn individual records into a list maintained by us.
List.Transform(list as list, transform as function) as listIn essence, we will be extracting the items of the original List individually, extracting the data we need, and directly solving whether this item is here or not. For this comparison, in the simplest variant, we will use the character ”?”, which we can place after individual name fields so that if they are not found in the record and the “error” value is placed instead of “error” and thus avoids a mass failure during execution.
#table(type table [Id = number, Name = text], List.Transform(Source[p], each {_[id]?, _[name]?}))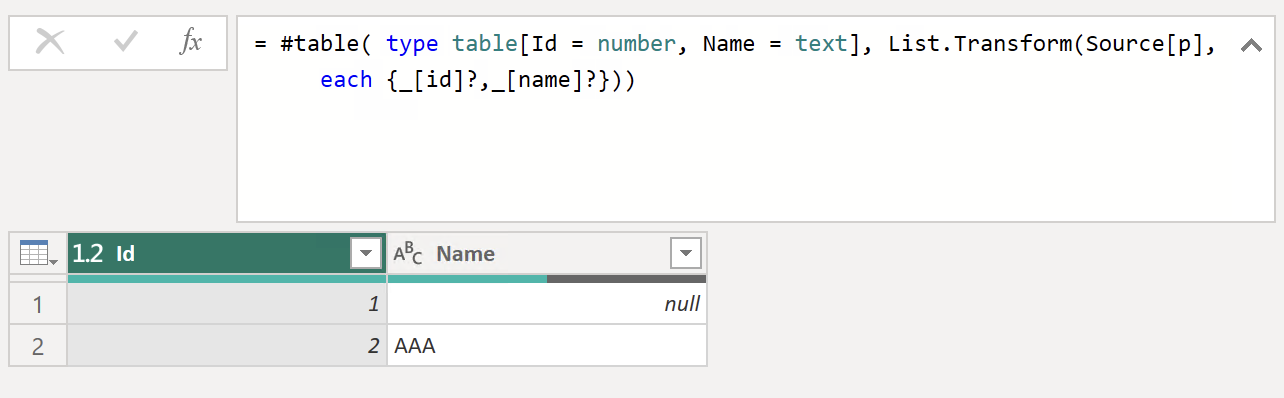 Result table
Result table
It looks good like this. We made the Table, renamed the columns, and set the data types in one step.
But how do the individual procedures compare in terms of speed?
Speed comparison of the mentioned methods
I modified all the methods to have the data in the same result style. Or, if we had a table, the columns would have the same name and data types.
 Prepared queries
Prepared queries
But it’s hard to tell on a small sample of data, so I created a noticeably larger JSON file so we can adequately test it:
 Generated larger JSON
Generated larger JSON
And now, all you have to do is run individual queries and measure their evaluation time using diagnostics. The results are as follows:
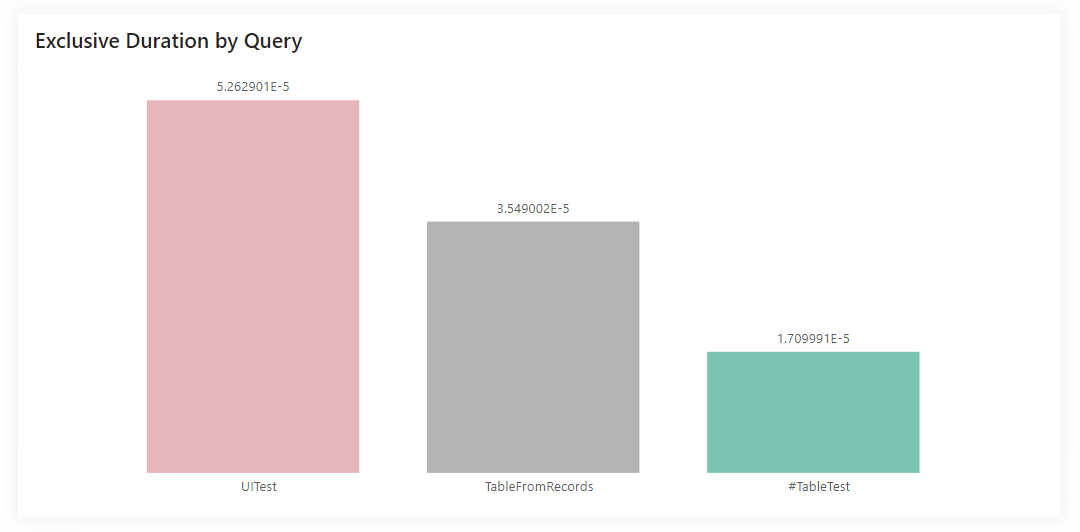 Results
Results
Summary
But if I take all three mentioned methods, which one should I use? The fastest one! And it just depends on the definition. If you are okay with the update speed, go with the easiest and fastest path for you to create. However, if you are serious about your data and know that it will grow, choosing the procedure that will be the fastest from the point of view of data processing is a good idea. So… the #table() variant.

