



It is an alternative to REST API and enables users to fetch data from multiple sources using a single query. Compared to REST API, GraphQL is much more flexible and allows users to retrieve only the data they need, reducing the amount of data transferred between the client and server. It also uses a single endpoint, reducing the number of requests made to the server. It is a platform and programming language-independent specification, meaning it can be used with any language and on any platform.
GraphQL is defined by an API schema written in the GraphQL schema definition language. Each schema specifies the types of data that users can request or modify, and the relationships between these types. The term “resolver” is often mentioned in relation to GraphQL. It refers to a function or functions responsible for fetching data for a specific field in the schema and provides instructions for converting the GraphQL operation into data. The operations supported by GraphQL are:
- Query for querying data
- Mutation for modifying data (CREATE, UPDATE, DELETE + Custom operations)
- Subscription for subscribing to real-time data. It is a way to push data from the server to the client when the data changes.
Within the defined data types, it is possible to define relationships between them. Relationships can be one-way or two-way and can be defined using keys or custom functions. Additionally, custom data types that are not part of the GraphQL schema can be defined. GraphQL also supports functions that allow filtering, sorting, and pagination of data, meaning users can retrieve only the data they need and do not have to fetch all the data at once. However, it is necessary to always define all the fields that you want to retrieve. There are no wildcards like “*“ that would return all fields.
Supported Fabric Items
Within Microsoft Fabric, GraphQL can be used to query the following Fabric items in specific modes based on the supported types of operations.
| Item | Types of operations |
|---|---|
| Warehouse | READ / WRITE |
| Lakehouse (SQL Analytics Endpoint) | READ |
| Mirrored Database (SQL Analytics Endpoint) | READ |
| Datamart | READ |
This means that currently only Warehouse supports modifying data using GraphQL, making it the only item that supports Mutation operations. These operations must be explicitly defined within the GraphQL schema. However, this is currently automatically generated based on the schema of the respective item and cannot be manually modified. This ensures a consistent approach to data access and prevents errors in querying. Warehouse also automatically generates create mutations. Update and Delete mutations are currently not generated, but this functionality can be achieved through stored procedures. If a stored procedure exists within Warehouse, the corresponding GraphQL endpoint can generate a mutation for executing it, serving as a replacement for the missing Update and Delete mutations.
A single GraphQL item can be used to query multiple Warehouse, Lakehouse, Mirrored Database, and Datamart items simultaneously. However, it is not possible to establish relationships between them as defined in the GraphQL schema. Relationships always work within a single item.
GraphQL is now part of Microsoft Fabric in the context of Data Engineering, where it can be enabled in the Admin portal. It can be configured for specific sets of users who then have the ability to create it.
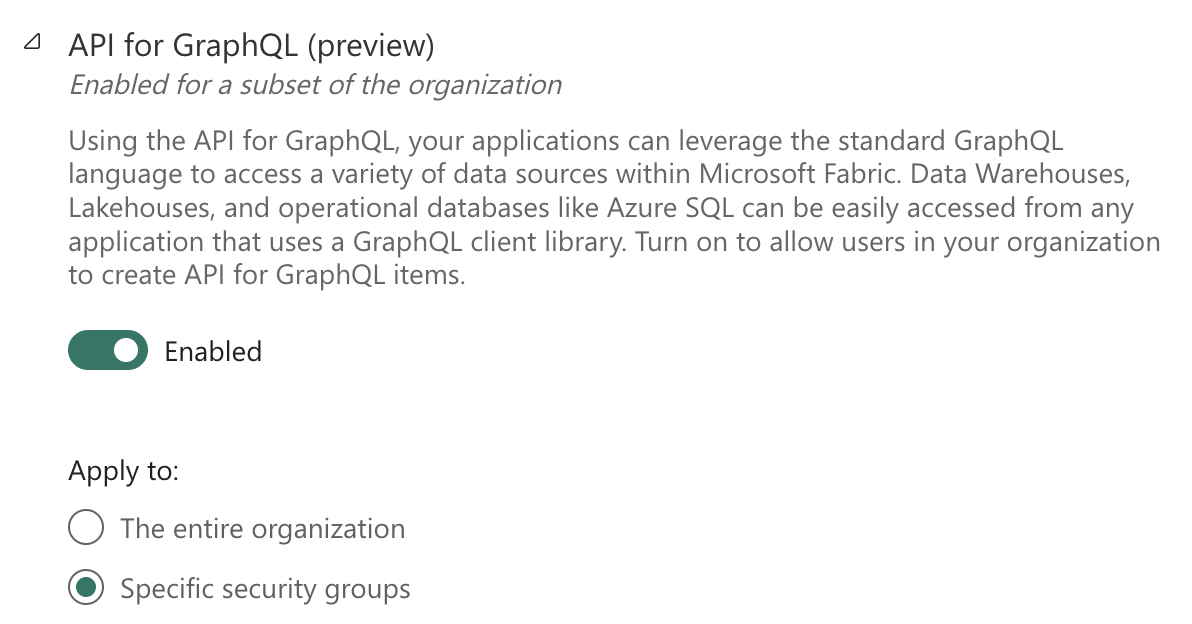 Tenant settings - API for GraphQL
Tenant settings - API for GraphQL
This setting can also delegate rights to individual capacity admins to potentially disable this feature within their capacity. Currently, it is not possible to limit GraphQL to specific items, meaning that if GraphQL is enabled, it is enabled for all items available within Fabric for a given author and does not have to be limited to the same workspace.
Connecting Data Sources to GraphQL
After creating a GraphQL item, the user is redirected to a canvas that prompts them to connect to available items (Warehouse, Lakehouse, Mirrored Database, and Datamart).
 Blank GraphQL canvas
Blank GraphQL canvas
In this canvas, the user can select individual tables to be used within the GraphQL item. This automatically generates the schema and, if applicable, mutation operations for those tables. Note: Relational relationships created within the item are not transferred to the schema and must be defined manually later.
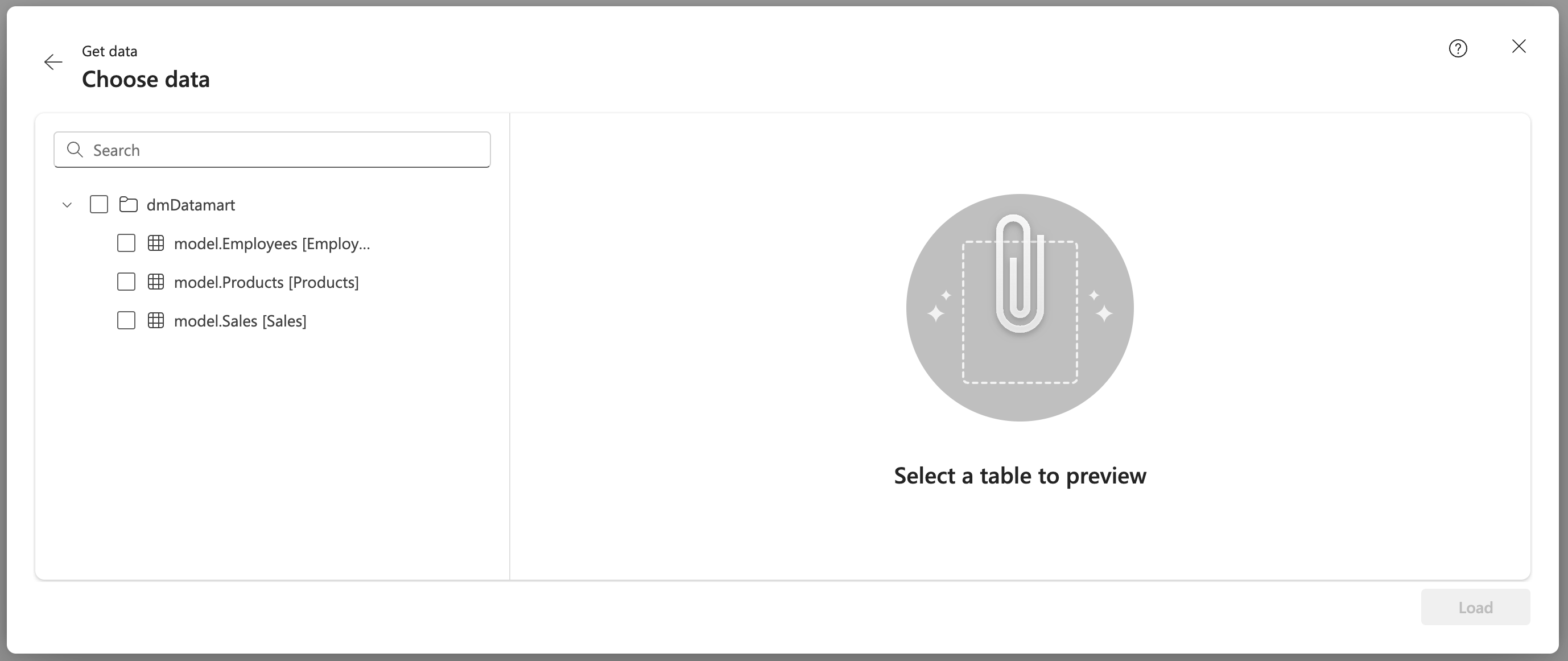 Table selection from Datamart
Table selection from Datamart
Depending on the item, different naming conventions for schemas and supported stored procedures are displayed.
 Selection from Warehouse with two schemas and one stored procedure
Selection from Warehouse with two schemas and one stored procedure
After connecting to the data, the original canvas is divided into multiple sections - Schema Explorer, Query Editor, Query Variable Editor, and Query results.
- Schema Explorer displays all available tables and schemas for the item.
- Query Editor is used to write queries for data.
- Query Variable Editor is used to define variables used in queries.
- Query results display the results of data queries.
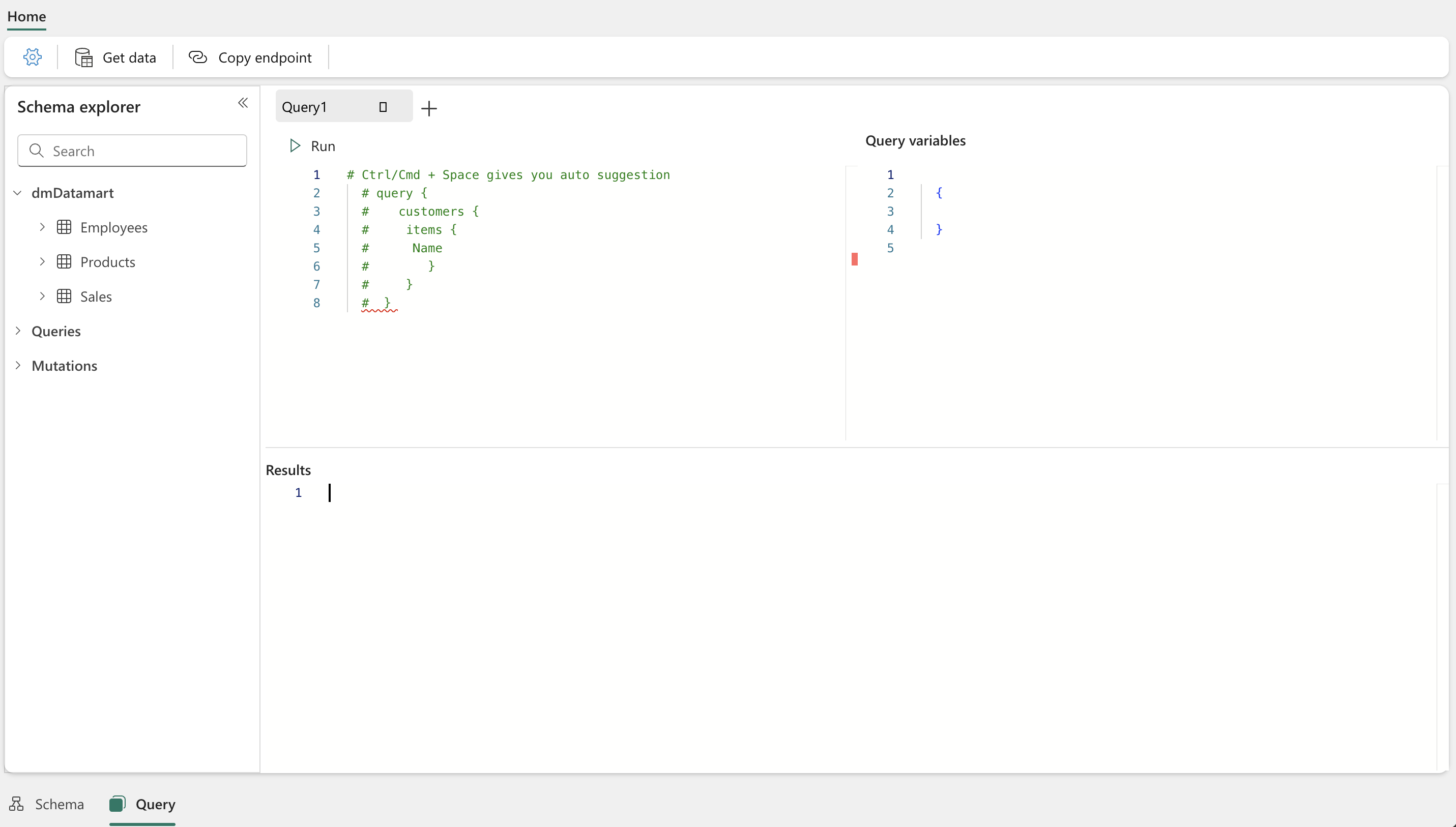 GraphQL connected to Datamart
GraphQL connected to Datamart
If the user selects a table from another data source with the same name as an existing table, an error would occur because the table name must be unique within the entire schema. In such cases, the user is alerted that the name is already in use and must choose a different name using the Resolve button.
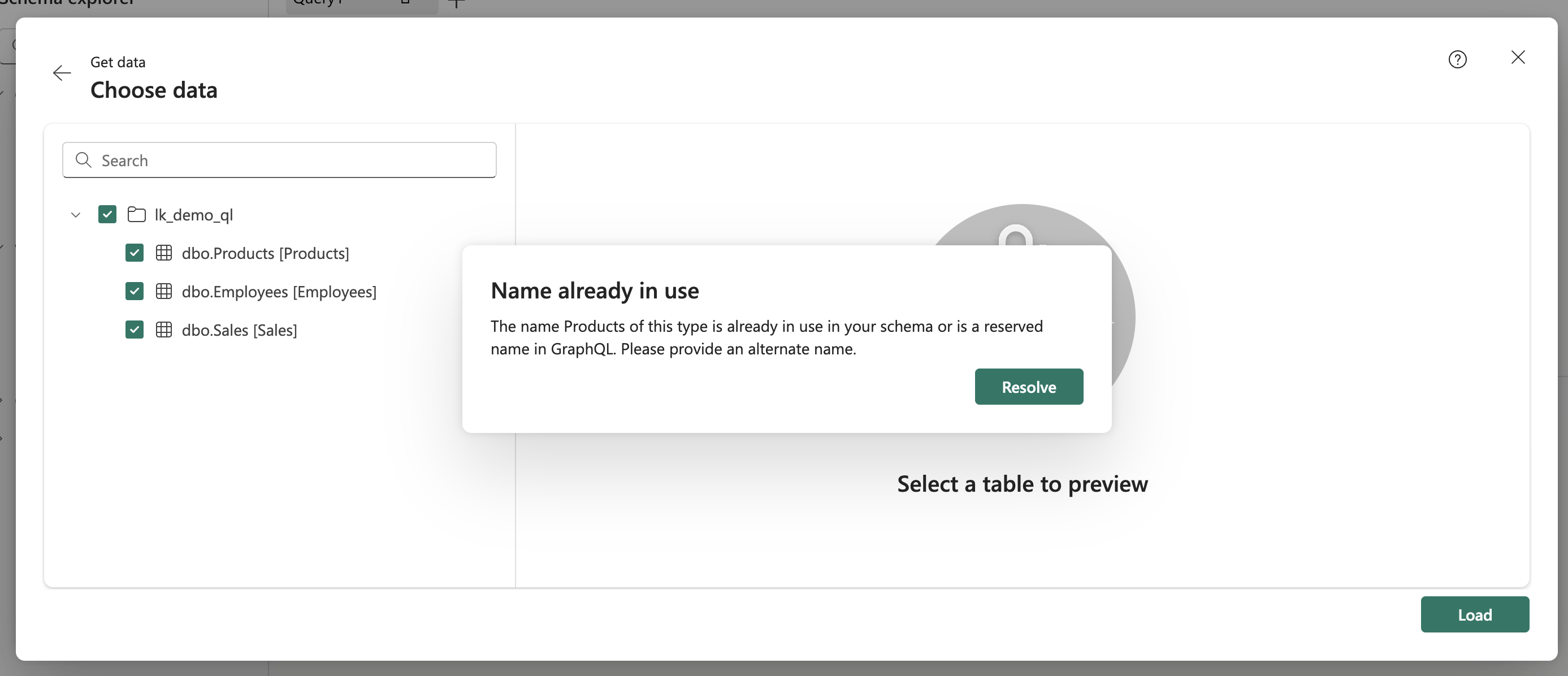 Name already in use
Name already in use
Each connected data source is metaphorically represented as a folder containing its tables within the Schema Explorer. Queries and Mutations are displayed together.
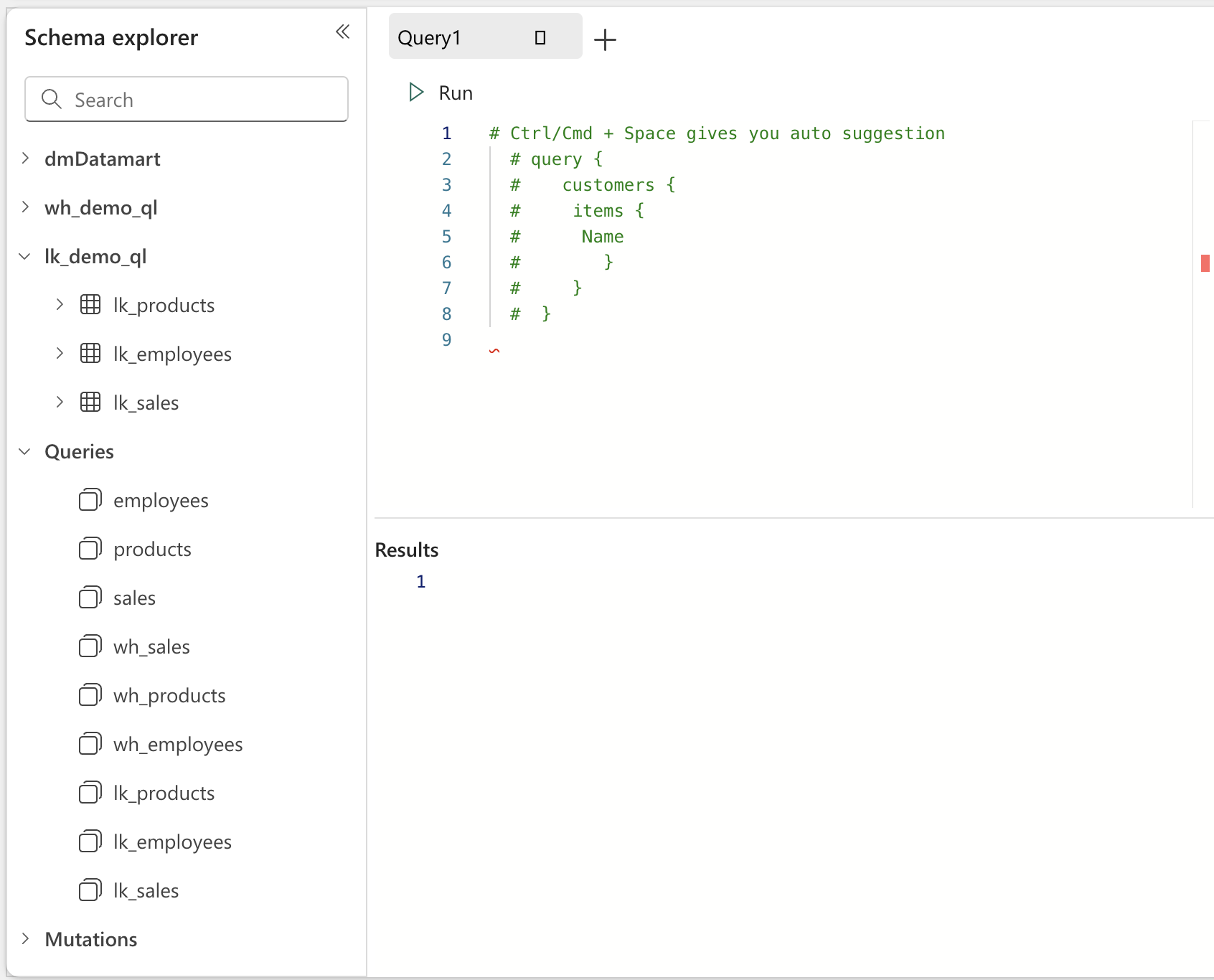 Schema Explorer with multiple data sources
Schema Explorer with multiple data sources
Therefore, it is important to be careful with naming conventions when creating tables to easily distinguish and use them in queries. Using a prefix may seem like a good idea, but it may complicate and make queries less clear. Fortunately, individual tables can be renamed later!
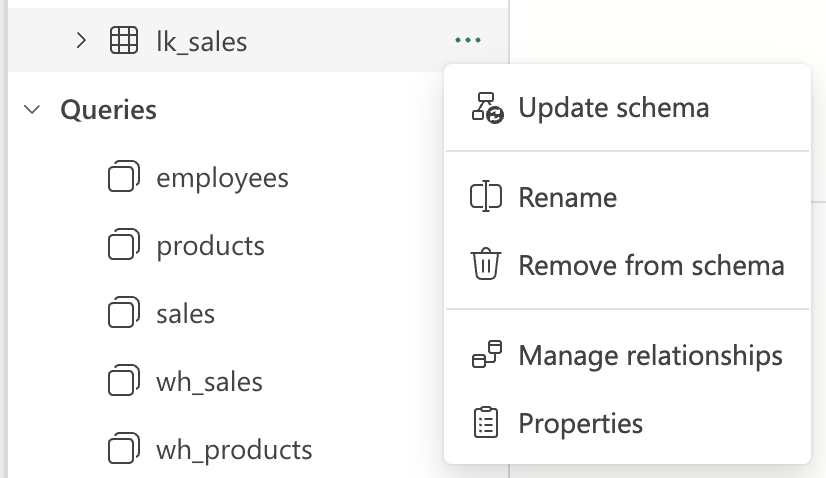 Options of tables
Options of tables
The author of the GraphQL item has the ability to remove tables or specific columns from the schema. This can be useful when not all columns of a table are needed in data queries. This can be done through the ellipsis icon “…“ next to the column name > Remove from Schema.
Creating Relationships Between Tables
It is possible to create relationships between tables manually within the Query Editor. Relationships can be one-way or two-way and can be defined using keys. They can only be created between tables from the same data source. One-way relationships mean that when querying one table, you can retrieve related records from the other table. In the case of two-way relationships, the same relationship extension is applied to the table that the relationship is referring to, but in reverse. If this setting is not enabled, it would mean that you can retrieve data referring from one table to the other, but not vice versa.
Unfortunately, in the current situation, it is necessary to create this relationship manually twice through the ellipsis icon “…“ next to the table name > Manage relationships > New relationship. This is where the relationship between tables can be defined.
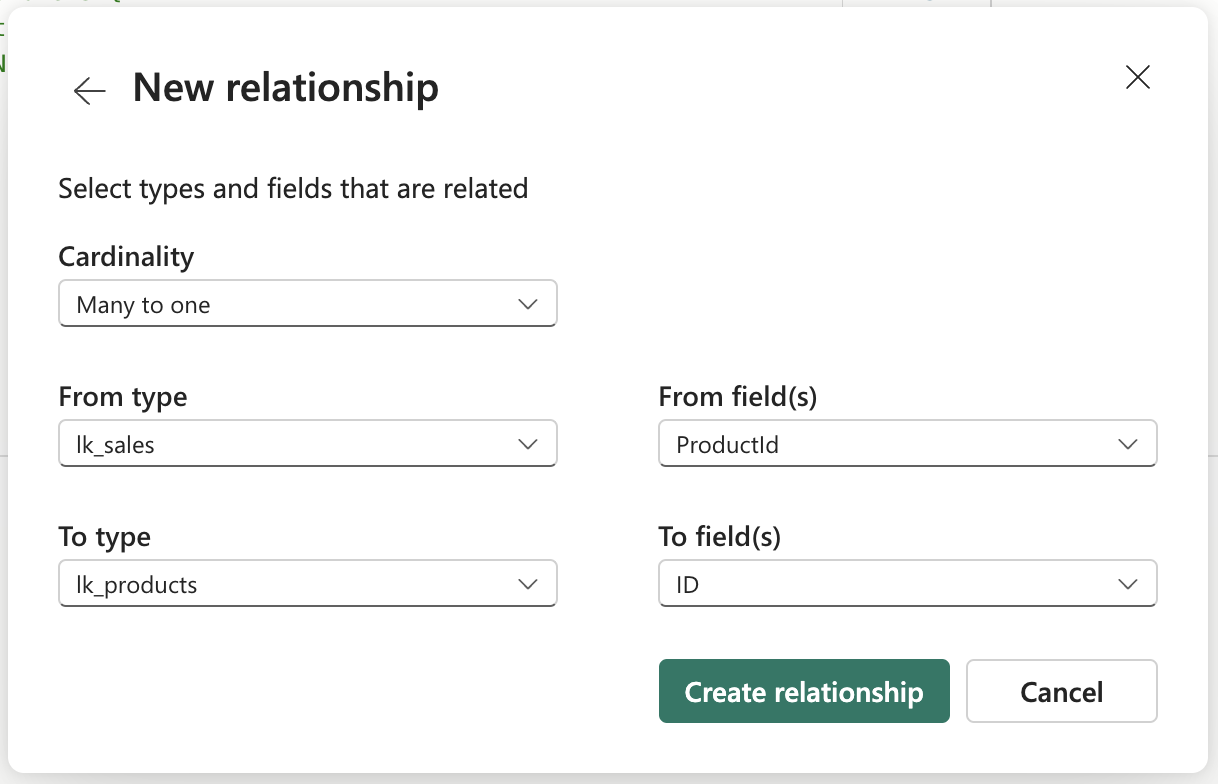 Defining relationship
Defining relationship
After saving the relationship, a relationship extension is automatically created in the schema, which can be used in data queries, and additional relationships can be created. For example, creating the exact reverse relationship to achieve bidirectionality.
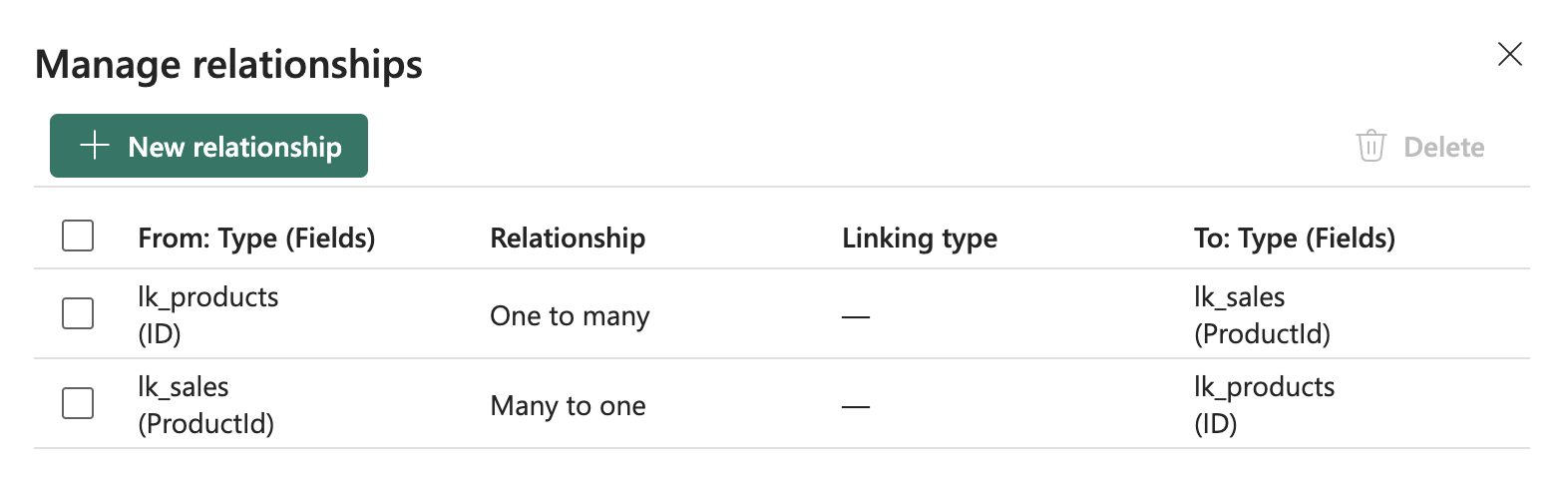 Dual Relationship
Dual Relationship
Relationships are then displayed in the Schema Explorer as additional fields with an icon representing the relationship to another table.
 Relationship Column in Schema Explorer
Relationship Column in Schema Explorer
By default, this field is named after the table to which the relationship is created. However, this can be confusing from a semantic perspective. For example, if we have a table “Sales” and a table “Employees”, the field “Sales” in the Employees table would make sense because one employee can make multiple sales. But in the Sales table, the field “Employees” would be confusing because one sale can be attributed to only one employee. Therefore, it is possible to rename this field to make it more meaningful. Instead of “Employees”, it could be “Employee”. Even this small change can greatly improve the clarity and comprehensibility of the schema and subsequent data queries.
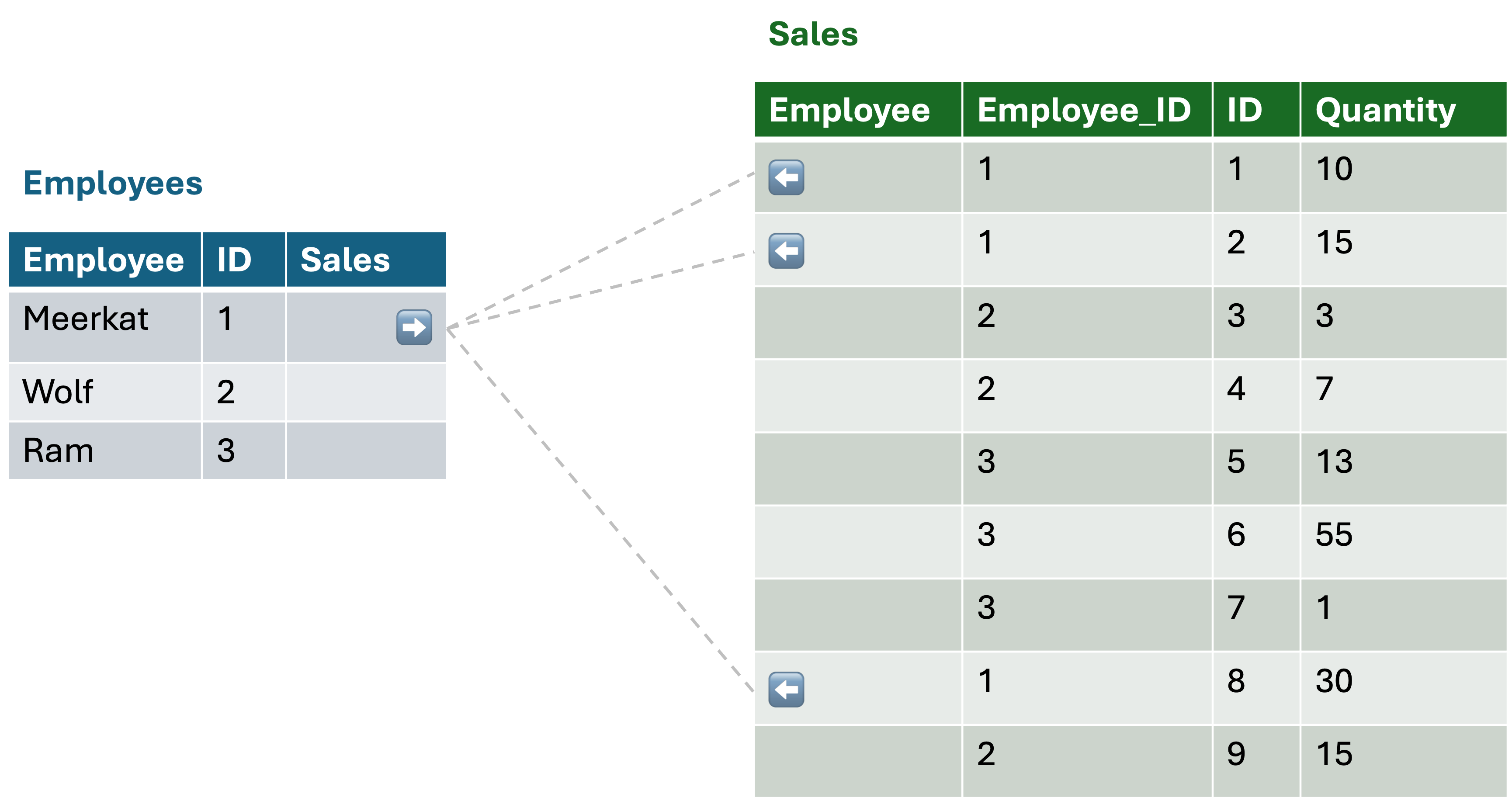 Relationships
Relationships
Querying Data
As mentioned before, when querying data using GraphQL, the operation used is Query. This operation is initiated with the keyword query, followed by the selection of tables and the desired columns within them. In the context of Microsoft Fabric implementation, columns are defined within the nested object items. The overall query syntax is very similar to the structure of JSON:
query{ # <--- Query initiation
sales { # <--- Table selection
items{ # <--- Declaration of columns to be retrieved
ID # <--- Column selection
Customer
Note
ProductId
Quantity
}
},
products { # <--- Another Table
items{
ID
Title
Note
}
}
}Within a table, additional information can be requested besides the content:
- endCursor: pagination token to retrieve more records
- hasNextPage: boolean value indicating if there is another page of records
- __typename: provides the original name of the declared type within the schema
Their usage can be helpful for implementing pagination or obtaining information about the data structure. However, to fully utilize pagination, it is necessary to understand how the token obtained from the endCursor is used. It can be used within functions that allow filtering and sorting data. Specifically, the functions after, filter, first, and orderBy. These functions are written within parentheses and can be combined. For example, if we want to filter data and retrieve only the necessary information, we need to construct the condition. However, symbols like < or > are not used here. Instead, keywords are used:
- eq (equals)
- neq (not equals)
- gt (greater than)
- lt (less than)
- gte (greater than or equals)
- lte (less than or equals)
- isNull (is null)
query {
sales(filter: { ID: { eq: 50 } }) { # <--- Filtering only to records with ID 50
items {
ID
Customer
Note
ProductId
Quantity
},
endCursor, # <--- Receive pagination token
}
}To implement pagination, you can use the after function with the previously obtained token. However, if the previous query contained a function like (first: 5), it is recommended to use it again when using the next token. Otherwise, you may retrieve data in a larger range than the original query.
query {
sales(first: 5, after: "######" ) { # <--- Receive only the next 5 records (###### replace with token)
items {
ID
Customer
Note
ProductId
Quantity
}
}
}If you want to query data through relationships between tables, you first need to declare the columns within items and use the linking column. You must define the columns from the second table that you want to retrieve. However, there is a difference in syntax between the 1:M side and the M:1 side of the relationship.
# Sales - Employees (M:1)
# Employees - Sales (1:M)
query {
sales {
items {
ID
Quantity
SaleDate
employee { # <--- M:1 side of the relationship
Title # <--- Will return a single record
}
}
},
employees {
items {
ID
Title
Role
Salary
sales { # <--- 1:M side of the relationship
items { # <--- Will return an ARRAY of Sales records
SaleDate
Quantity
}
}
}
}
}Nesting relationships is possible to any depth, but it may slow down the query. Therefore, it is important to consider whether it is necessary to nest relationships deeply and always request only the columns that are truly needed. Additionally, these relationships provide the option for nested filtering and sorting. It is possible to retrieve data from the “Employee” table based on data from the “Sales” table. For example, if we want to retrieve all salespeople who sold a specific product or sold more than 5 units in a single transaction.
query {
employees(filter: { sales: { Quantity: { gt: 5 } } }) { # <--- Filtering only to Employees with at least one Sold Quantity greater than 5 in the Sales table
items {
ID
Title
Role
Salary
}
}
}Executing Mutations and Stored Procedures
Another very useful ability, as mentioned before, is the use of mutations and the execution of stored procedures. The beginning of the query is the same within the mutation operation. Since mutations are pre-defined within Microsoft Fabric, it is possible to refer to them directly. As mentioned before, within the Warehouse, mutations for creating new records are automatically generated. In case we want to create a new record in the Employees table, we can use the following query:
mutation {
createEmployees(item: { ID: 100, Title: "Meerkat" }) {
result # <--- Required field to return the result of the mutation
}
}Similarly, if we want to execute our own stored procedure, we need to know the name of the procedure or its mutation. Be careful to always provide all the input parameters required by the procedure.
mutation {
executedeleteProduct(id: 100) {
result
}
}If you want to modify the name of the procedure, you need to update the schema using the ellipsis icon “…“ next to the table name > Update schema > ellipsis icon “…“ next to the procedure name > Rename. However, this will not remove the “execute” prefix. It is automatically added to the procedure name in the schema definition.
 Rename Stored Procedure
Rename Stored Procedure
Variables
Variables can be used within queries to make them more dynamic. They are defined within the Query Variable Editor and can be used within the query by referencing them with the $ symbol. Variables work in the same way as variables in any other language. Each variable needs to be declared with a name used to access its stored value. In GraphQL, variables are defined as an additional JSON, where attributes are used as variables. This can be useful when you want to filter data based on user input or when you want to reuse the same query with different parameters.
{
"id": 100
}It is still necessary to declare them within the desired operation and assign a data type, otherwise they would not be usable. However, once they are declared, they can be used in any query:
mutation variableFunction($id: Int!) { # <--- Declaration of the variable for the mutation purpose
executedeleteProduct(id: $id) { # <--- Using the variable in the mutation
result
}
}Similarly, they can be used in filters or in setting the number of records we want to retrieve:
{
"id":360,
"first": 10
}query variableFunction($id: Int!, $first: Int!) { # <--- Declaration of the variables for the query purpose
sales(first: $first, filter: { ID: { eq: $id } }) { # <--- Filtering only to records with ID equal to the variable and retrieving only the specific ammount records defined by the variable
items {
ID
Customer
Note
ProductId
Quantity
}
}
}Conclusion
GraphQL is a powerful tool for querying data from multiple sources using a single query. It provides a flexible and efficient way to retrieve only the data needed, reducing the amount of data transferred between the client and server. It is a platform and programming language-independent specification, meaning it can be used with any language and on any platform. Within Microsoft Fabric, GraphQL can be used to query Warehouse, Lakehouse, Mirrored Database, and Datamart items. It is possible to create relationships between tables, query data, mutations, and executing stored procedures, and use variables to make queries more dynamic. GraphQL is a valuable addition to Microsoft Fabric, providing users with a powerful tool for querying data and enabling them to retrieve only the data they need.
Currently, GraphQL can only be used with a user token. Microsoft provided a tutorial on receiving it in the external application by logging into Microsoft Entra ID. Link to tutorial

