



Let’s start by introducing what orchestration is and why it’s important to talk about shared resources. Orchestration is a discipline focused on managing and coordinating individual items or control elements to collectively manage the flow of our data operations. In the context of Fabric, this involves managing notebooks, dataflows, pipelines, stored procedures, semantic model updates, and many other items, activities, and services that may even be outside of Fabric.
Orchestration
Pipelines are often used for this task, helping to trigger these activities at the right time, thus aiding in the harmonization of the entire process to avoid unnecessary delays or triggering activities that might not have the correct inputs (e.g., missing data from previous transformations).
If such harmonization does not occur, we might encounter situations like this.
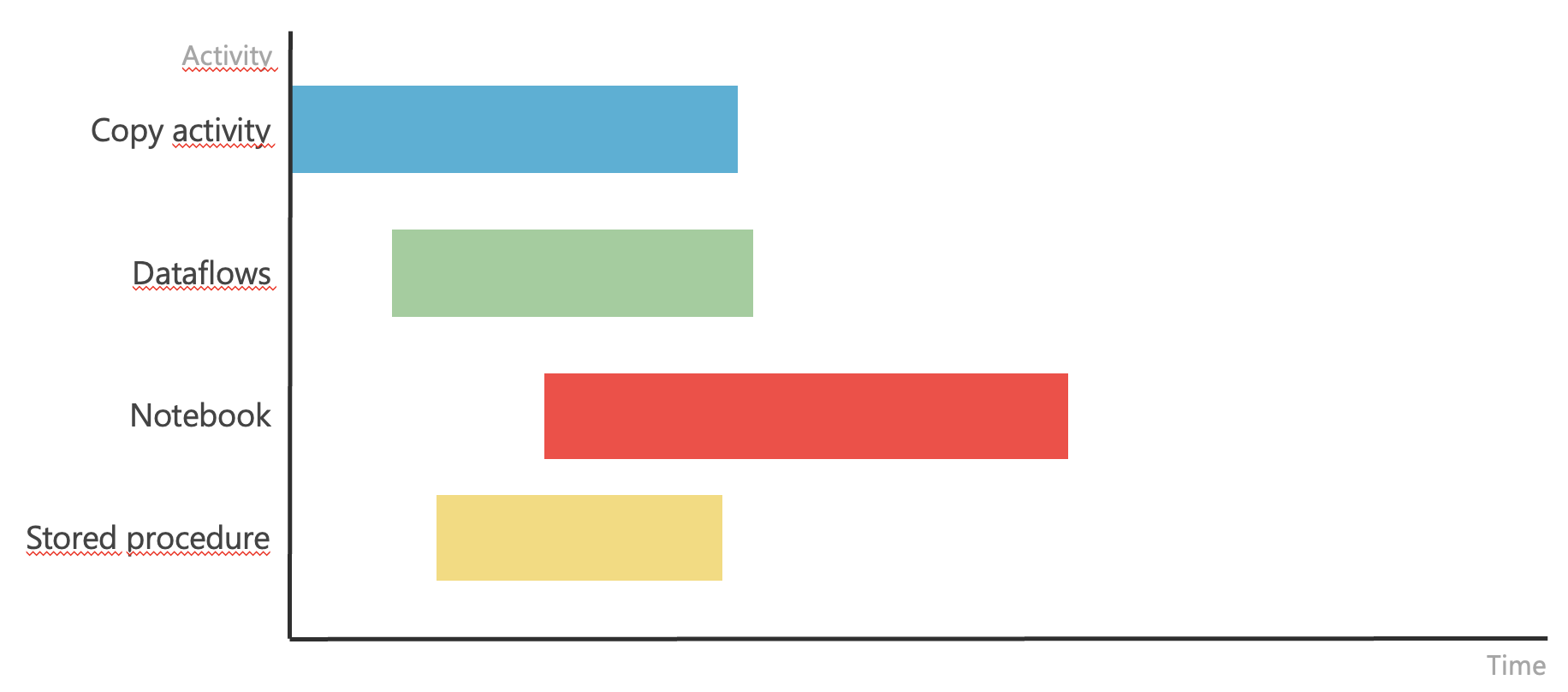 Disharmonized schedule of items
Disharmonized schedule of items
Individual process steps do not follow each other and can be triggered independently. If this is indeed the case, they can be run independently using their own timers. However, if the steps follow each other and depend on each other, they need to be triggered in a specific order and with specific inputs. This scenario might look like this after adding dependencies.
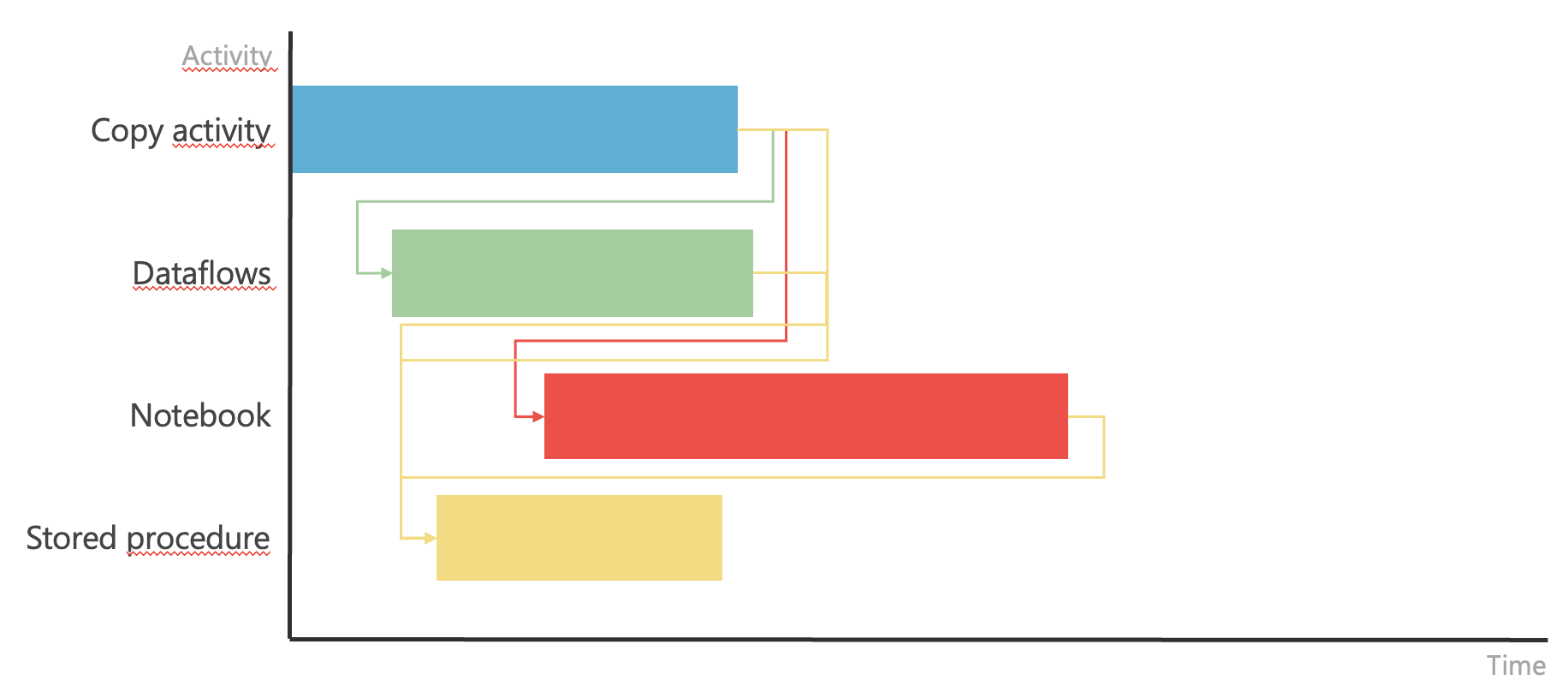 Item Continuities
Item Continuities
In such a case, it is necessary to ensure that these activities are also triggered at the correct time. This is exactly where Pipeline or Apache Airflow can be used. They allow us to define individual steps, when they should occur, and their dependencies. Often, we can also pass input parameters that can be used during execution. The result of harmonization within orchestration might look like this.ion might look like this.
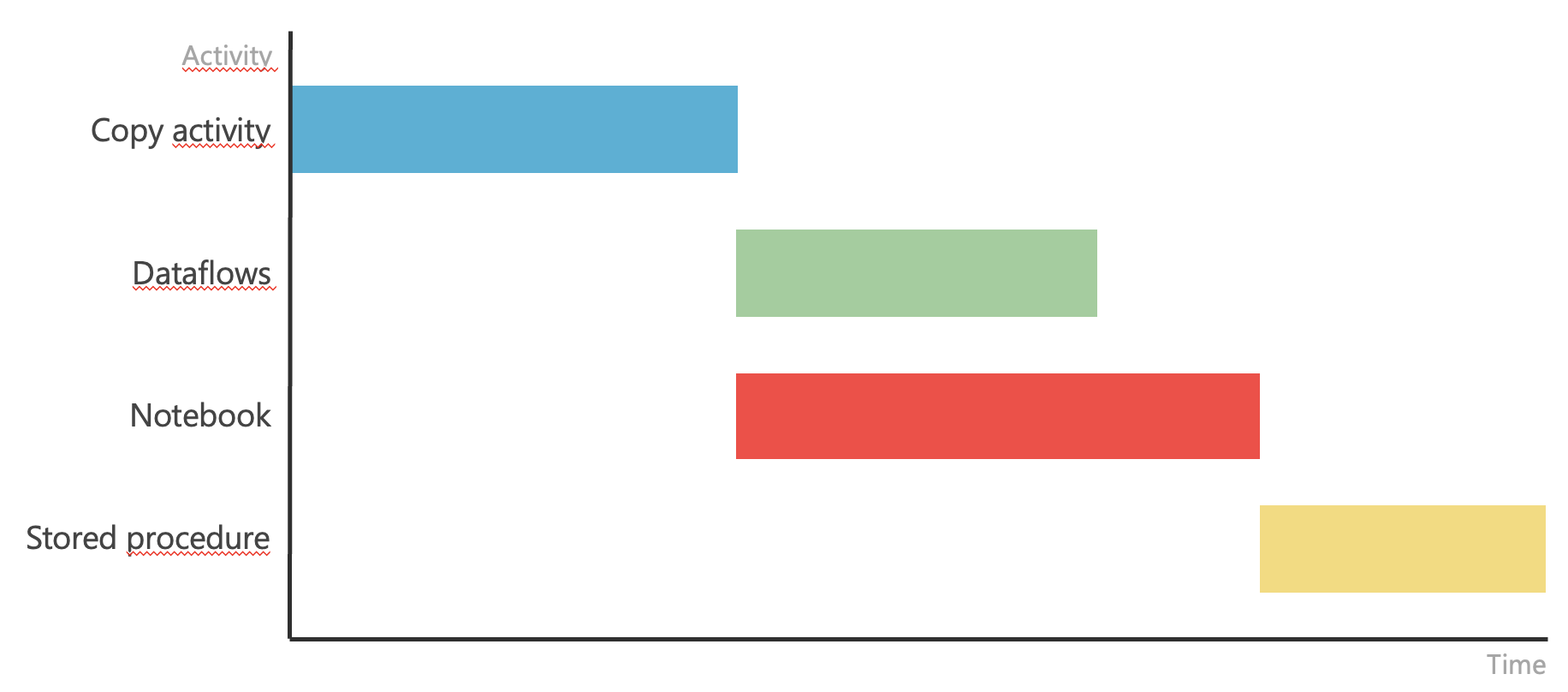 Harmonized schedule of items
Harmonized schedule of items
Such a harmonized process can then be triggered and easily monitored to ensure everything occurred in the correct order, with expected results, and potentially avoid triggering subsequent transformation steps or initiate a restart of a previous step in case of an error, and only then automatically trigger the dependencies.y then automatically trigger the dependencies.
Besides the two mentioned options (Pipeline and Apache Airflow), other options can be used for orchestration. These include using API or Notebooks themselves. Why and when we should use them will be discussed later in this article. But to make sense of it, we need to introduce what shared resources are.
Shared resources
The first clear perspective is that within Microsoft Fabric capacities, we have a limited number of CU (Capacity Units) available at any given moment. These CUs are directly proportional to the capacity we have purchased ~ Microsoft Fabric Licenses.
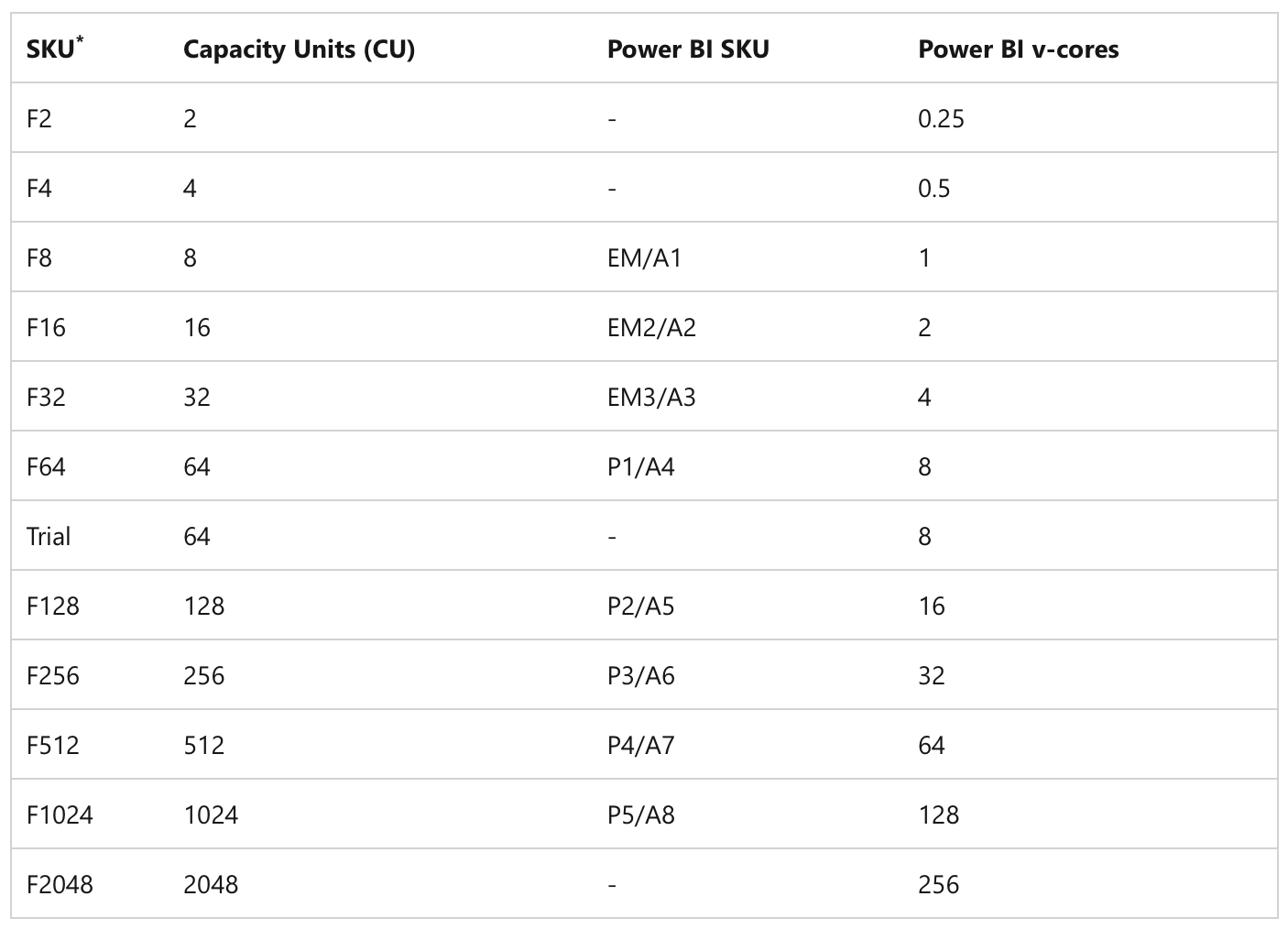 Table of Fabric SKUs
Table of Fabric SKUs
CUs are thus a unit that tells us how many resources we can use at any given second. If we exceed them, delays, slowdowns, or even rejection of new inputs into the system occur ~ Throttling limits.
This first fact must be kept in mind. It applies to all items within Microsoft Fabric capacity, regardless of whether we are talking about background or interactive operations. The second point, which is extremely critical from the perspective of notebooks, is the limit on how many pyspark sessions can run simultaneously within our capacity. This limit can be particularly unpleasant for beginner developers or companies just starting with Microsoft Fabric.
Why? Because if, for example, we have four developers currently creating and testing their notebooks, it can easily happen that a timed notebook does not get space in the capacity and has to wait for space to free up or even be rejected. The same can happen to another developer who needs to work at that moment.
To better understand this limit, we need to look at another table prepared for us in Microsoft Learn regarding Spark concurrency limits.
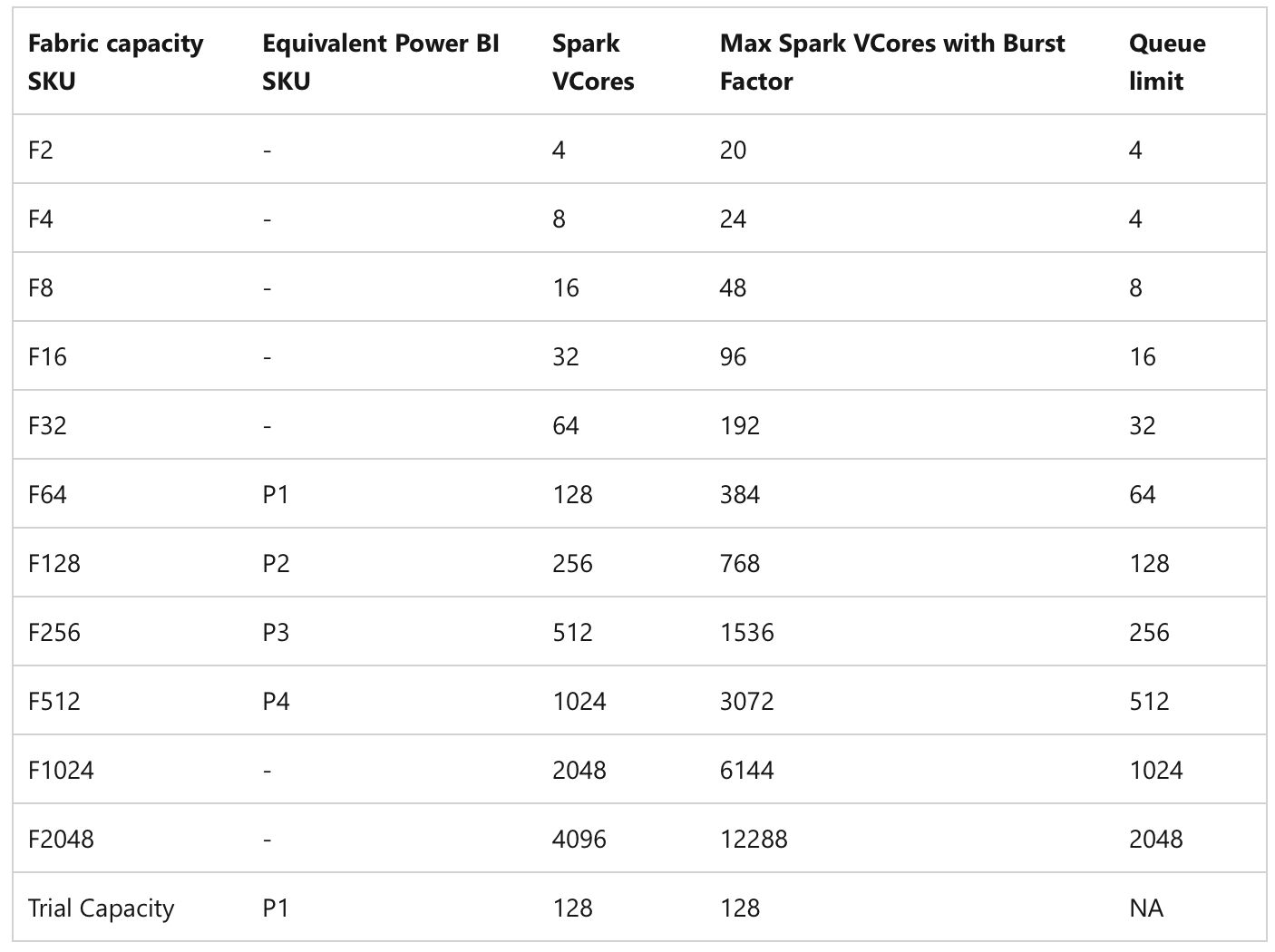 Spark VCores provided based on SKU
Spark VCores provided based on SKU
The table clearly shows that depending on the SKU, Spark VCores (1 CU = 2 Spark VCores) are provided for our use. It also shows that there is something called a Queue. The Queue is essentially a line that tells us how many notebooks that cannot be run at that moment are waiting for space to free up and will be automatically triggered once space is available. Since the whole process works on the FI-FO (First In - First Out) method, it is important to remember that they will be triggered in the exact order they were added to the queue, and if the queue is full, they will be rejected. Therefore, it is important to properly manage when and how notebooks should be triggered, and if, for example, a pipeline should trigger 5 parallel notebooks, it is quite possible that they will not fit into the available resources and will start returning this type of error.
HTTP Response code 430: This Spark job can't be run because you have hit a Spark compute or API rate limit. To run this Spark job, cancel an active Spark job through the Monitoring hub, or choose a larger capacity SKU or try again later.Spark Sessions
To better understand Sessions and their capacity consumption, it is important to know that for utilizing the overall Apache Spark Compute, there are Spark Pools, which execute the instructions of our transformations within sessions. These sessions are essentially individual instances that contain all the necessary information for running our notebooks. This information includes, for example, Spark settings, libraries we have installed, or settings for connecting to data sources. All this information is stored within a single session and is available to all notebooks that are run within this session. We can divide pools into two basic types:
- Starter Pools
- Custom Pools
The main difference between them is that Starter Pools represent the default layer that can be used for sessions within Microsoft Fabric. These clusters are always active and can therefore be used almost immediately. It is possible to set a different number of nodes for them, which can provide for their sessions, and here we are basically talking about 1-10 nodes. Custom Pools, on the other hand, represent the possibility to set your own specifics that will be used for incoming sessions. They can be customized in terms of the size of the nodes, autoscale, and executor allocation. However, they are not always active and need to be started before they can be used. This can take a while, so your session may not be available immediately. (Here you can find out, how in case of billing these pools works ~ Billing and Utilization)
It is very important to mention that we have different types of sessions. Classic ones, where one notebook uses one session. It is also possible that one user can have multiple sessions because they needed more notebooks during development and forgot to turn off the session in individual notebooks. Yes, one user can very easily use up the capacity for the entire company. However, there are High concurrency sessions. These allow sharing a session among multiple notebooks at once. This is very useful when we want to be considerate of other users and processes. To be able to share a session, it is necessary to follow the rules mentioned in the documentation:
- Be run by the same user.
- Have the same default lakehouse. Notebooks without a default lakehouse can share sessions with other notebooks that don’t have a default lakehouse.
- Have the same Spark compute configurations.
- Have the same library packages. You can have different inline library installations as part of notebook cells and still share the session with notebooks having different library dependencies.
These High concurrency sessions are also not a panacea and need to be manually started in the respective notebooks when we want to work with them. To be able to use them at all, they need to be enabled within the workspace.
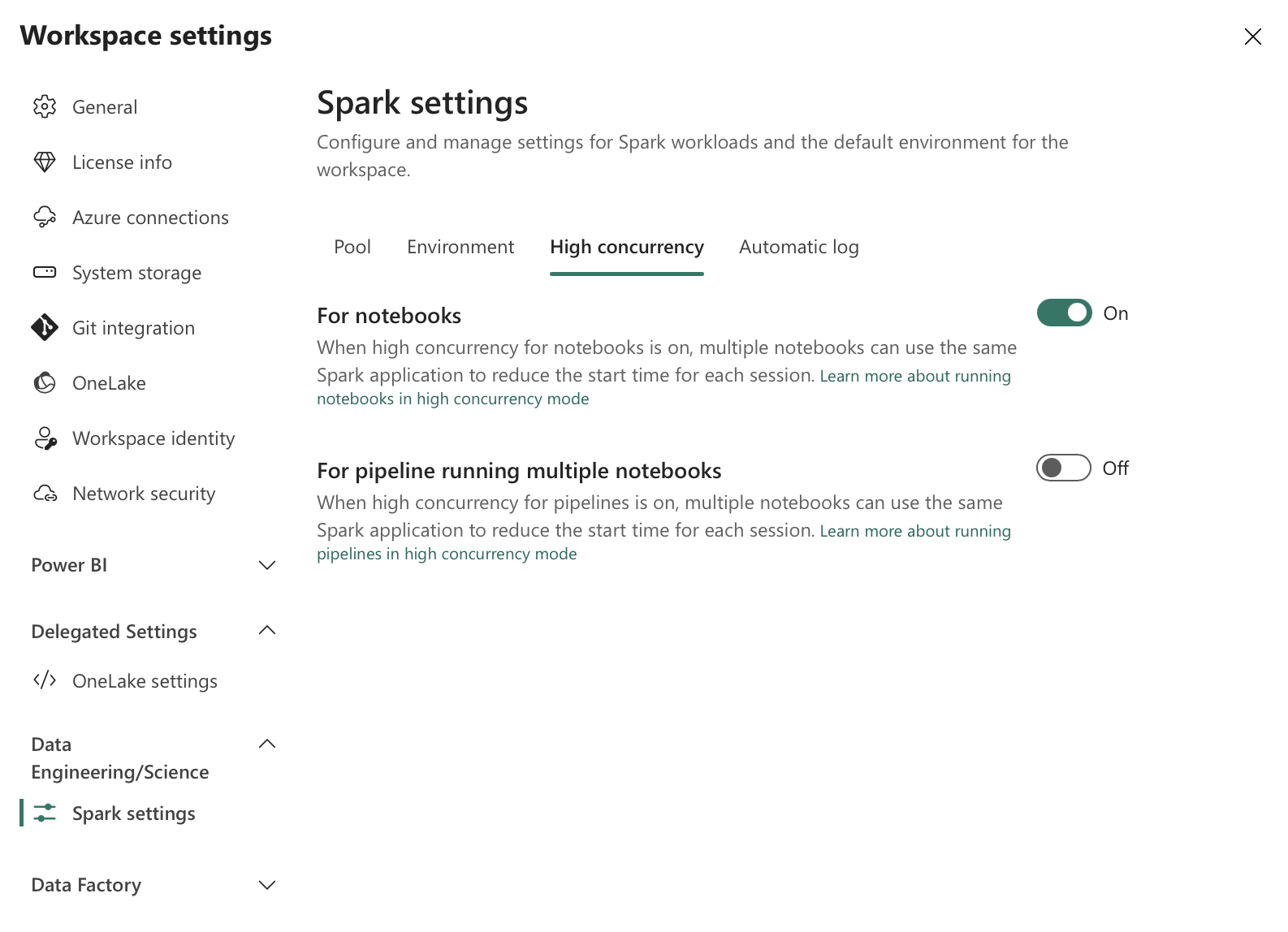 Workspace High Concurrency Settings
Workspace High Concurrency Settings
Orchestration of Notebooks
If we were to talk about a corporate environment where it is necessary to run, for example, a pipeline for orchestrating more, then besides harmonizing activities, we also need to talk about harmonizing resources and individual runs that use these resources. Of course, it is possible within, for example, one pipeline to set it up so that individual notebooks are triggered sequentially, ensuring that only one session is used at any given moment. However, it sometimes happens that it takes a while for a session to free up, and meanwhile, another one is already being triggered. Nowadays, this is not so common, but in the early public preview phase of Microsoft Fabric, this happened relatively often. At that moment in time, there were two sessions. This approach is quite valid today, but CAUTION!
Switching sessions leads to other problems. Each session that starts needs to add all resources and settings to itself. This in itself takes initialization time, and if one session ends, it needs to be cleaned up. Adding to this, if another notebook starts in the meantime, either waiting in the queue or arriving 0.01ms earlier, potential delays and problems start to accumulate.
In the above settings, it is already possible to use High concurrency sessions within pipelines. This also helps solve the whole problem. However, it is important to remember that all notebooks in such a case must share the exact same settings for Spark compute, use the same libraries, etc., according to the documentation. The pipeline then decides whether to attach the notebook to the session or not.
If we want to have a higher certainty that the notebook will attach to the session, we can use a slightly different approach to the whole problem. We can use a Notebook that will trigger other notebooks within its session. This notebook can manage which notebooks will be triggered in parallel or sequential order. So, very similar to how it can be achieved within a Pipeline. To do this, we need to use a special package called notebookutils. It contains many useful functions for working with the Microsoft Fabric environment.
NotebookUtils for orchestration
From runtime version 1.3, it is not necessary to install this package because it is part of the environment by default. For lower versions, it needs to be installed using the following code.
import notebookutilsWithin this package, there is a module called notebook. As the name suggests, it focuses on operations with notebooks. Besides functions like create(), update(), delete(), there are three functions that should interest us for orchestration. These are run(), runMultiple(), and validateDAG(). We will get to the last one later.
Functions for orchestration
Let’s start with the run() function. As the name suggests, this function serves to trigger one notebook. This function has several parameters that need to be provided. The first is the name of the notebook we want to trigger. The second is the timeout in seconds, which determines the time after which the notebook run will be terminated for exceeding the time limit. The default value is 90 seconds. The third is the option to pass parameters that we want the notebook to use. The last is workspaceId, because from version 1.2, it is possible to trigger notebooks in other workspaces than the one where the triggering notebook is located using this package.notebook is located using this package.
notebookutils.notebook.run("notebook name", <timeoutSeconds>, <parameterMap>, <workspaceId>)A notebook triggered this way will be on the same session as the notebook that triggered it. We are thus using similar behavior as with High concurrency sessions. If we wanted to trigger notebooks sequentially but using the same session, we could use this function and pass it the individual notebooks we want to trigger. If it were a lower number of notebooks, this is quite a valid solution. However, if we wanted to trigger notebooks in parallel or generally wanted to trigger more and properly manage their dependencies, it is more suitable to use the runMultiple() function.
notebookutils.notebook.runMultiple(<DAG>, <config>)It accepts either a list of notebooks to be triggered in parallel mode or by providing a complex data structure (dict or JSON string). Subsequently, it is possible to define a certain form of configuration parameters that can affect the output values. Specifically, these are displayDAGViaGraphviz, showArgs, and showTime. The first can be used to display a graph showing the dependencies between individual notebooks defined through the mentioned complex structure and also represents whether the notebook was successfully executed. The second and third can be used to display the arguments passed to individual notebooks and the execution time. Both of these parameters are tied to the graph that is to be displayed. The default value for all these parameters is False.
%run magic command:
Besides the mentioned functions, there is also the option to use the magic command %run. This also triggers another notebook. You can read more details in the link, including a warning that nesting more than 5 levels of notebooks will return an exception. However, within this run, all resources are shared because there is no physical triggering of another notebook but embedding the given notebook into the current one. This means that if the embedded notebook contains some libraries or variables, they will also be brought into the triggering notebook and can cause collisions and overwriting. This can be especially dangerous if we want multiple developers to develop these notebooks. The probability of collision would be very high, also because one developer might use a different default lakehouse than the triggering one.
%run [-b/--builtin -c/--current] [script_file.py/.sql] [variables ...]Supported DAG for Notebooks
DAG stands for Directed Acyclic Graph. This represents a form of graph where individual nodes of this graph are directed towards other nodes and structured to avoid cycles. Every node can be in graph exactly once. In the context of notebook orchestration, this graph can be used to manage dependencies between individual notebooks. Since individual operations can always be performed in a certain common sequence or parallelism. Similarly, it is true that we do not want to perform the same operation multiple times.
Will be also great to mention, that the end of a graph doesnt need to be just one. DAG can have multiple ends in multiple branches.
This form of graph is supposed to help us establish the correct order in which notebooks should be triggered and potentially prevent triggering notebooks that depend on a notebook that has not yet been triggered or ended with an error and we do not have valid data. Under certain conditions, it may of course be desirable to trigger notebooks even if one of them ended with an error, and yes, this special scenario can be handled, but it is important to remember that it can cause other problems.
The expected DAG can be defined in two possible ways, as mentioned. Either as a list of individual notebooks to be executed. Since it is a simple list, there is no dependency, and they are triggered in parallel. Or it can be defined as a complex data structure, for example, a JSON string that will define individual dependencies and rules. DAG is not only used within Microsoft Fabric but is also part of the previously mentioned Apache Airflow. In any case, within the implementation used for Notebooks in Microsoft Fabric, we have quite a few useful attributes that can be used within the DAG definition.
Example of DAG code, which can be obtained using notebookutils.notebook.help(“runMultiple”):
DAG = {
"activities": [
{
"name": "notebook1", # activity name, must be unique
"path": "notebook1", # notebook path
"timeoutPerCellInSeconds": 90, # max timeout for each cell, default to 90 seconds
"args": {"param1": "value1"}, # notebook parameters
"workspace": "workspace1", # workspace name, default to current workspace
"retry": 0, # max retry times, default to 0
"retryIntervalInSeconds": 0, # retry interval, default to 0 seconds
"dependencies": [] # list of activity names that this activity depends on
},
{
"name": "notebook2",
"path": "notebook2",
"timeoutPerCellInSeconds": 120,
"args": {
"useRootDefaultLakehouse": True, # set useRootDefaultLakehouse as True
"param1": "@activity('notebook1').exitValue()" # use exit value of notebook1
},
# to ignore that child notebook attach a different default lakehouse.
"retry": 1,
"retryIntervalInSeconds": 10,
"dependencies": ["notebook1"]
}
],
"timeoutInSeconds": 43200, # max timeout for the entire pipeline, default to 12 hours
"concurrency": 50 # max number of notebooks to run concurrently, default to 50, 0 means unlimited
}
notebookutils.notebook.runMultiple(DAG, {"displayDAGViaGraphviz": False, "showArgs": False, "showTime": False})The example shows the default values set if the developer does not provide them. Besides, for example, input parameters passed within the args attribute, it is possible to use special functions available within this definition. These include @activity(“nameOfNotebook”).exitValue(). This function returns the value returned by a notebook that has already been triggered. Given that you may often need more time for processing or obtaining your data using notebooks, note the timeoutPerCellInSeconds attribute, which, as the name suggests, sets the default for internal cells of the triggered notebook. The default value is 90 seconds, which may be very little for certain operations (e.g., downloading data from asynchronous APIs).
Now to the really important part. This is the arrangement of notebooks in the order of individual nodes, or in our case, notebooks. Within the graph. The attribute dependencies is used for this within the supported structure. It determines on which notebook the current notebook depends and must be executed only after the previous one has been executed.
"dependencies": ["notebook1"], # It can be run after a successful run of notebook 'notebook1'.
"dependencies": ["notebook1","notebook2"] # It can be run after a successful run of both notebooks 'notebook1' and 'notebook2'.
"dependencies": [] # It can be run anytime, usually in the layer of initials notebooks.These examples can be represented as following chart:
It is also important to note that there is a default value for concurrency at the global level. This tells us how many notebooks can run in parallel, provided we have sufficient resources (Excerpt from the documentation on Microsoft Learn: The parallelism degree of the multiple notebook run is restricted to the total available compute resource of a Spark session.) The documentation clearly states that it is not good to exceed the default value of 50, as it leads to instability and performance issues due to high performance demands.
Example of executed DAG with the graph displayed:
DAG = {
"activities": [
{
"name": "NotebookThatAddsAValue",
"path": "NotebookThatAddsAValue",
"timeoutPerCellInSeconds": 90,
"args": {"myAwesomeParameter": 300},
},
{
"name": "SecondNotebookToBeRun",
"path": "SecondNotebookToBeRun",
"timeoutPerCellInSeconds": 120,
"retry": 1,
"retryIntervalInSeconds": 10,
"dependencies": ["NotebookThatAddsAValue"]
},
{
"name": "SecondNotebookToBeRunButInParallel",
"path": "SecondNotebookToBeRunButInParallel",
"dependencies": ["NotebookThatAddsAValue"]
},
{
"name": "LastNotebookToRun",
"path": "LastNotebookToRun",
"dependencies": ["SecondNotebookToBeRun","SecondNotebookToBeRunButInParallel"]
},
{
"name": "api_caller",
"path": "api_caller",
"workspace": "3f72c575-7017-49a4-82d2-a96aa7702cc8",
"dependencies": ["SecondNotebookToBeRunButInParallel","LastNotebookToRun"]
}
],
"timeoutInSeconds": 43200,
"concurrency": 50
}
notebookutils.notebook.runMultiple(DAG, {"displayDAGViaGraphviz": True, "showArgs": True, "showTime": True})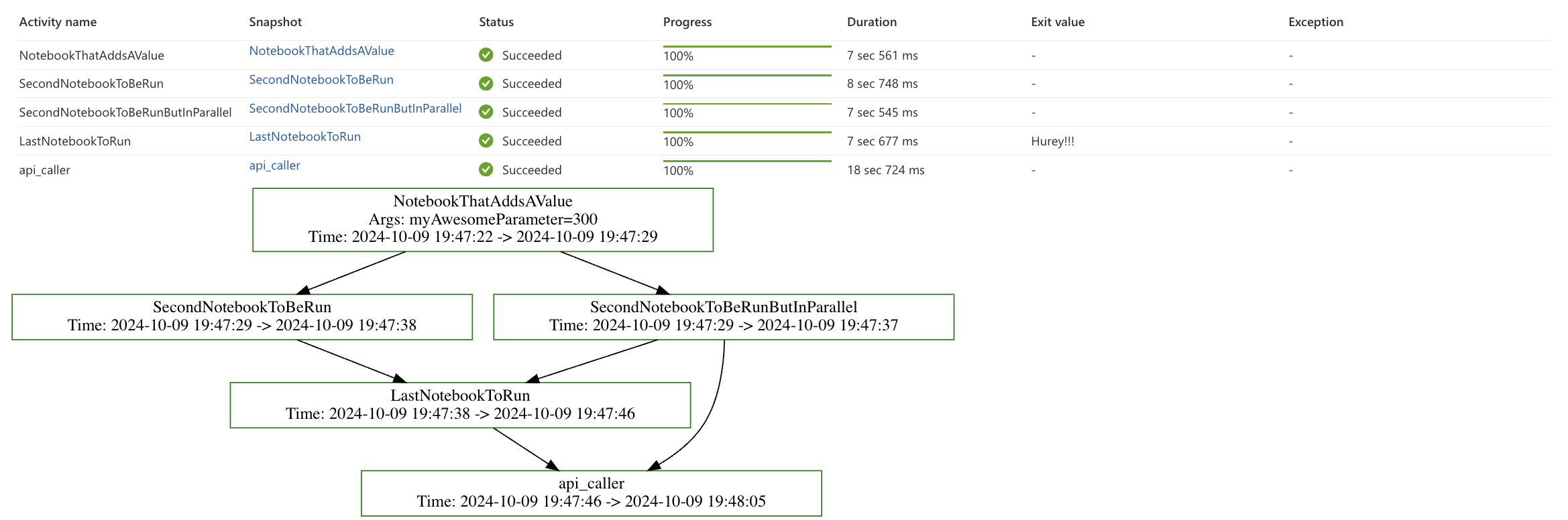 Successful run with DAG Graph
Successful run with DAG Graph
In the image, you can see that one notebook returns some output value. As mentioned earlier, notebooks can return some output. This can be further processed or passed to other notebooks. To make a notebook return some output, you need to use the following function:
notebookutils.notebook.exit("String that you want to return")This function not only returns a value but also closes the given notebook. If it contained more cells, they would not be executed. It is important to note that if a notebook is terminated this way, it always returns as “successfully” completed. Therefore, you need to handle Exceptions properly to decide when to return exit and when an actual exception should occur, preventing further graph traversal. If an exception occurs, the output looks as follows.
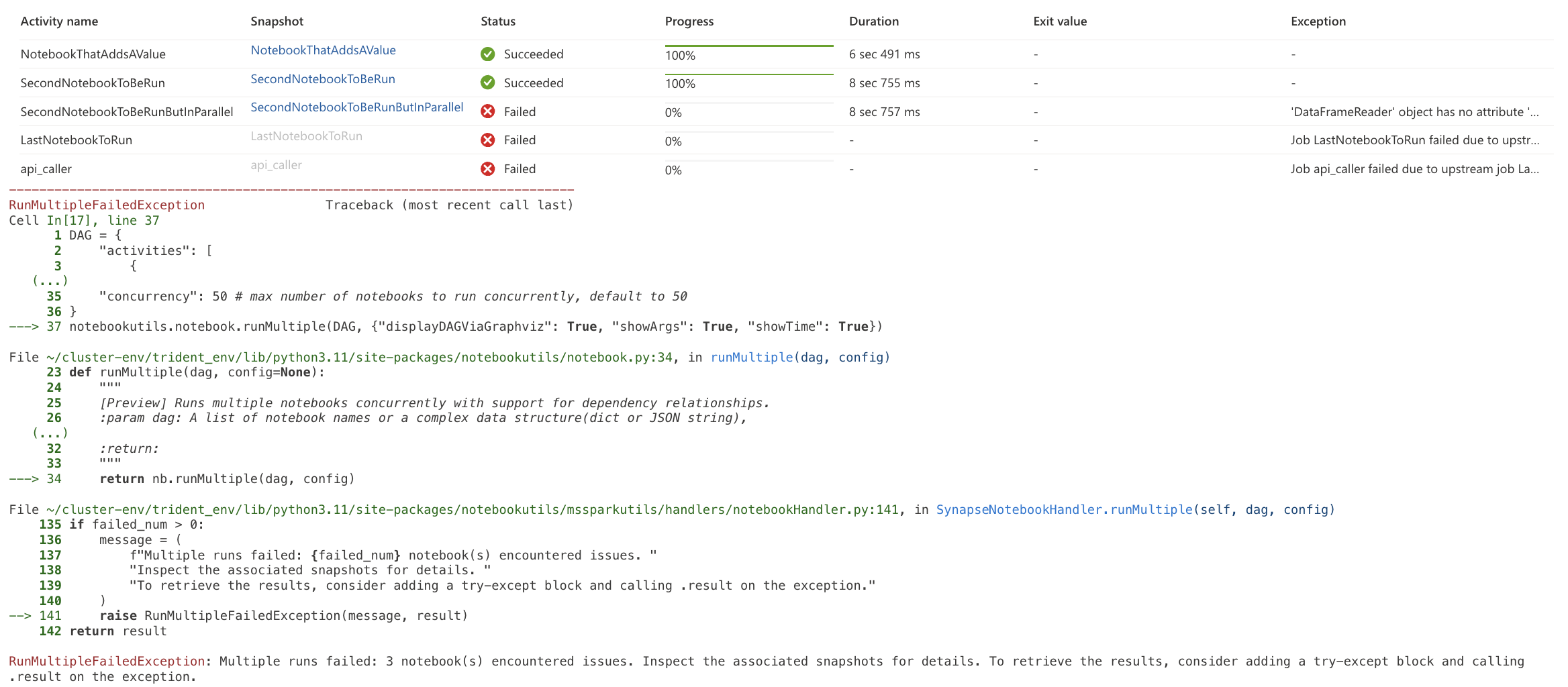 Failed run
Failed run
As I mentioned, sometimes even if a notebook fails, we still want to continue with the computation. It could be a lookup table that doesn’t change often or isn’t needed in further transformations and can be run later. In such cases, it is good to handle the possible output of such a notebook, for example, using try … catch.
try:
spark.read.parquet("") # Will cause an error
except Exception as e:
notebookutils.notebook.exit(f"Error occurred: {e}")The graph traversal will continue because the output in case of an error is still the exit() function, which, as mentioned, returns a successful output from the notebook.
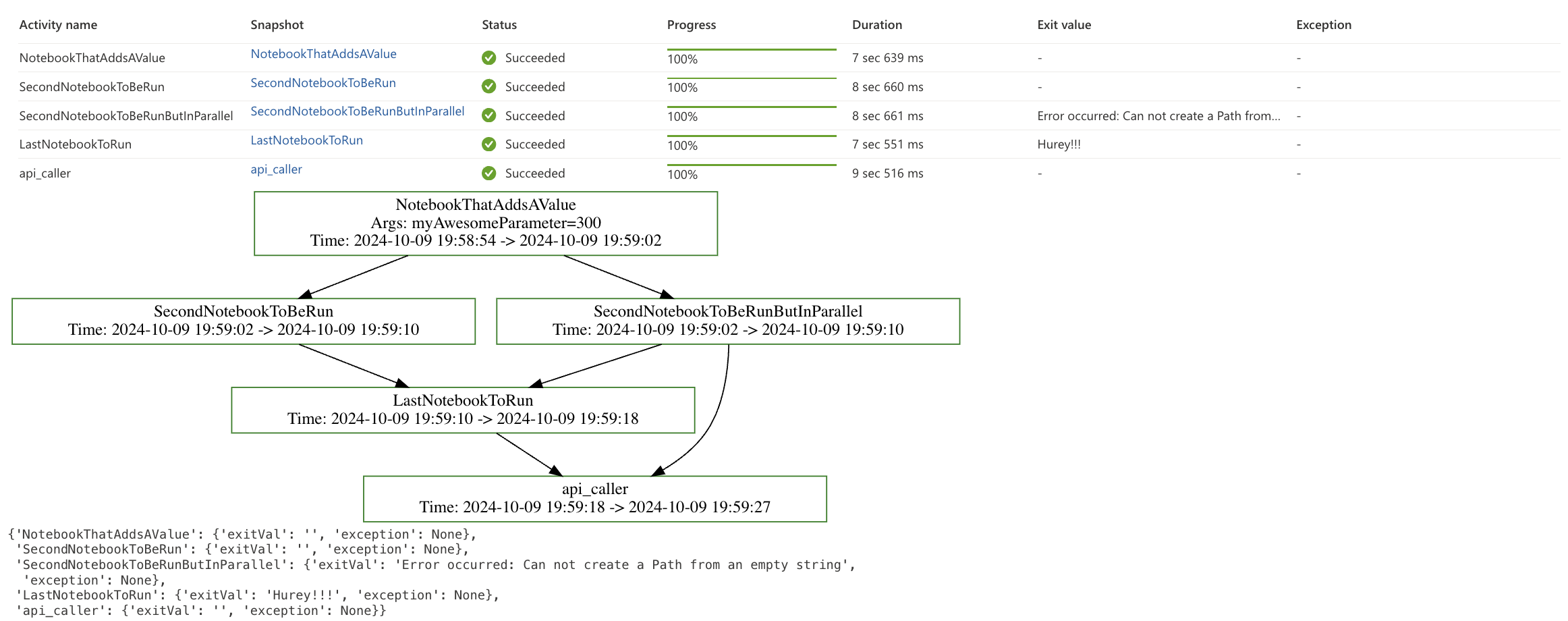 Fully executed graph with caught error inside
Fully executed graph with caught error inside
DAG Validation
When creating a DAG, especially a more complex form, it is good to verify that the form is correct and does not contain errors. This can be achieved using the validateDAG() function.
notebookutils.notebook.validateDAG(DAG)This function accepts our created definition as a parameter. If everything is fine, it returns True. If there is an issue with provided DAG, it prints the error that was found.
 Error in DAG definition
Error in DAG definition
Conclusion
Orchestration of notebooks within Microsoft Fabric is very important and needs to be managed correctly. It is essential to keep in mind that we have limited resources in terms of CU capacity and notebook concurrency. Notebooks can be managed by various items and can even manage themselves. Managing notebooks through Pipelines is visually very simple and user-friendly but can lead to problems where we cannot correctly manage dependencies and utilize session sharing. Even High concurrency sessions will not always be the answer due to the many limitations that apply to them. A possible suitable orchestration is to use a DAG within the runMultiple() function. This function allows us to manage dependencies between notebooks and use available resources more efficiently.
Within the DAG, it is essential to handle notebook outputs and possible errors that may occur correctly. If we want to use some output from a notebook, we need to use the notebookutils.notebook.exit() function and handle errors using try … catch. Thanks to the DAG definition, it is possible to run notebooks in other workspaces, allowing us to create a master notebook that will manage the entire graph traversal and keep track of which notebook was run and which was not. This way, we can manage the overall computation of the Silver layer and correctly time individual operations in sequence.
