




In a time of Fabric, it’s worth pointing out our three options for data ingestion.
- Data Pipelines with Copy Activity
- Dataflows Gen 2
- Notebooks
We must compare them to understand what each can offer us from different perspectives. To be able to compare them thoroughly, there are some guardrails that we need to set so that everything goes the same way.
Guardrails and assumptions
We have three Sharepoint lists. Each of them contains different data and different columns.
-
Employees
- 50 rows
- 10 inner columns
-
Products
- 350 rows
- 5 inner columns + 1 lookup column
-
Sales
- 12000 rows
- 7 inner columns
We need to get the data from these lists to our Lakehouse. But data needs to look like exactly as it looks in Sharepoint! We don’t just want IDs; we want values. Each method will store data in its own Lakehouse within its workspace. All of them will be measured in a Fabric Capacity Metric perspective to compare Duration(s) and Capacity Units (CU) usage. At the same time, we are interested in the laboriousness of such data migration and the ability to fulfill the assignment.
So we have a basis. It’s time to look at the first option to get this data.
Copy Activity
It is an activity within Fabric Pipelines that allows us to take data from one place and transfer it to another. It also allows us to change the data storage format.
The activity is straightforward, and basically, everything here is guided by the UI, which differs depending on whether we want to use the activity as such or get help from Copy Assistant.
 Copy data
Copy data
Since it will import data from several lists, I will use help from the Assistant, who will create a parametrized process at the end.
Initially, you have to choose your data source and continue by completing the prepared steps. Does it seem too simple? It is well! Someone put a lot of work into this component to simplify the integration process.
Anyway, yes, even Sharepoint Lists are here among the connectors.
 Sharepoint Lists Connector in Assistant
Sharepoint Lists Connector in Assistant
Either way, you need to log in to the data source. For Sharepoint Lists, we only have the option to log in using Service Principals. We already know the same option from DataFactory, where only this option exists for logging in.
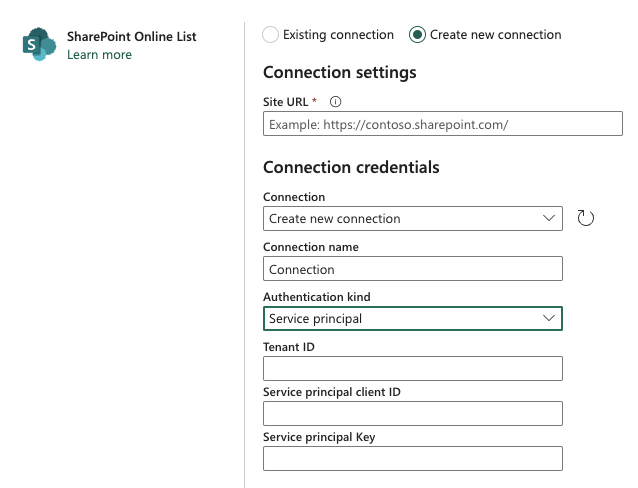 Service Principal Authentication
Service Principal Authentication
Immediately after logging in, we can select the individual sheets we want to obtain data from. Everything is augmented with a data view, which is critical for us because Lookup columns and even Choice columns have data stored slightly differently, and we need to see if we’re getting the data we need.
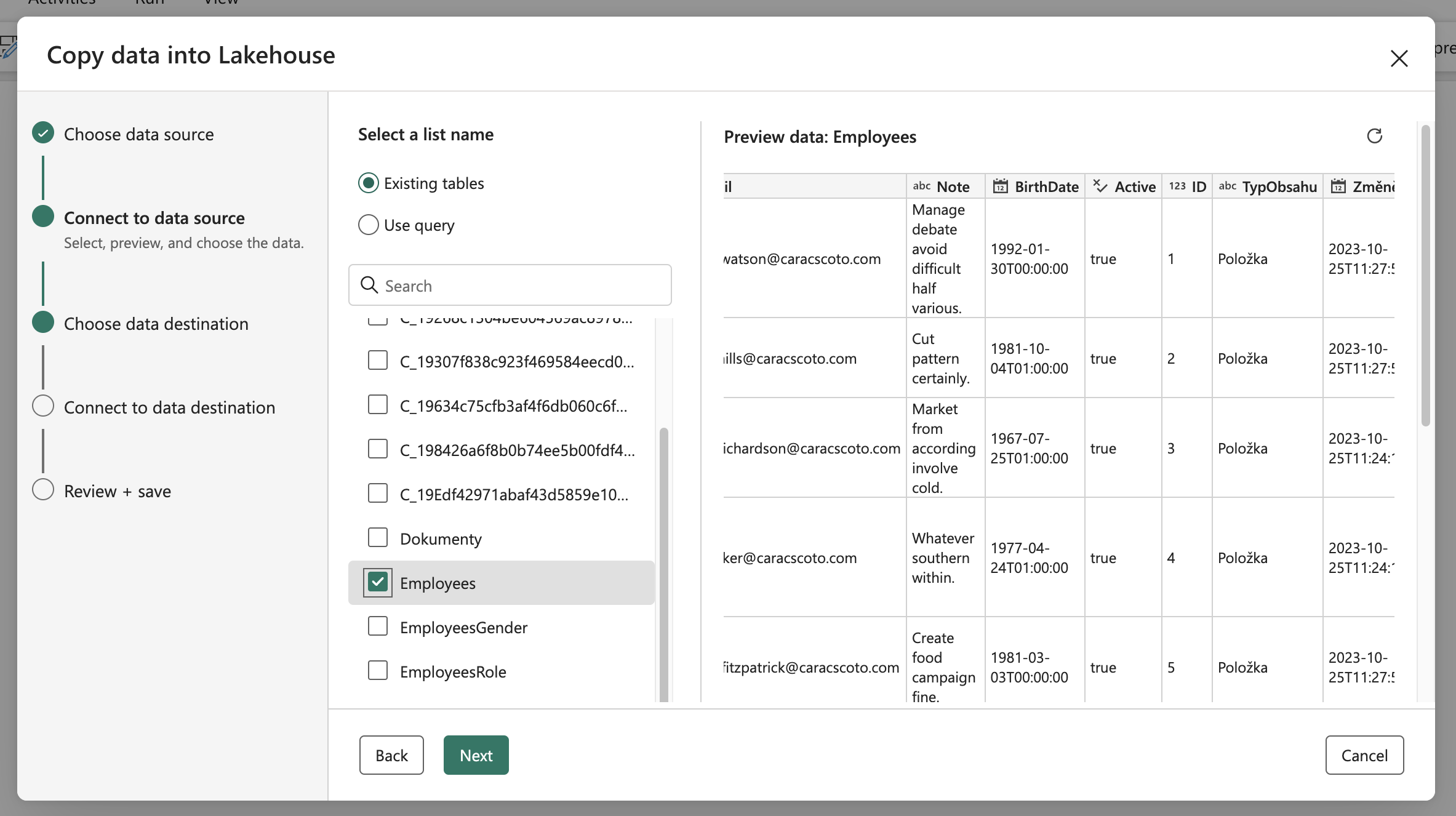 Data Preview
Data Preview
When checking the data from the preview, I found that the data from the Choice columns has been returned correctly, but unfortunately, not from the Lookup columns! For them, only their ID is returned in the column with the pattern <column_name>& “Id”. We can solve it by expanding the query through system queries using $select and $expand.
As part of this activity, there is support for custom queries that we can execute against the Sharepoint List. Like $select, which works great!
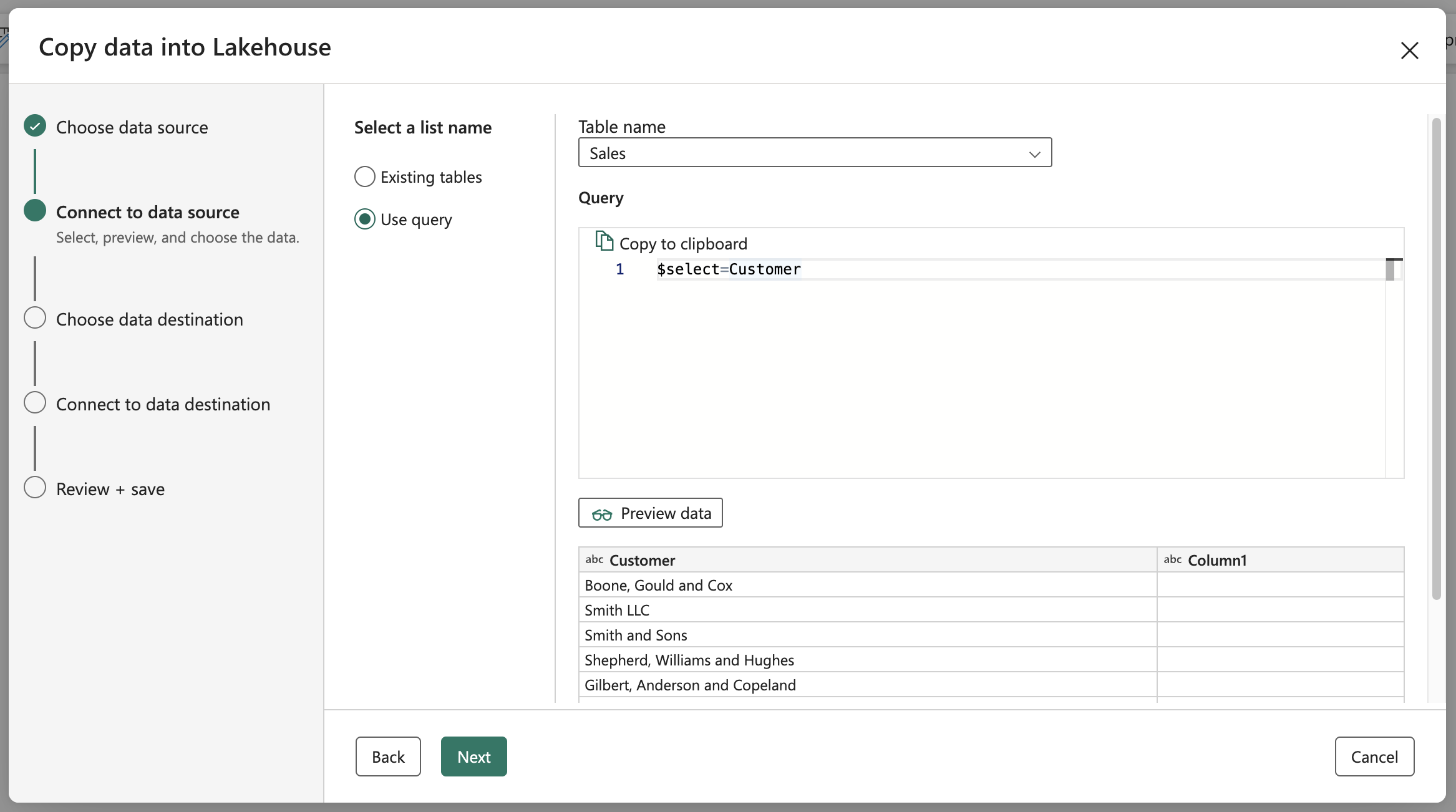 Custom query - $select
Custom query - $select
Unfortunately, I discovered that neither Data Factory nor Copy Activity within Fabric supports the $expand parameter. No error is returned when it is validly used, but an empty column occurs.
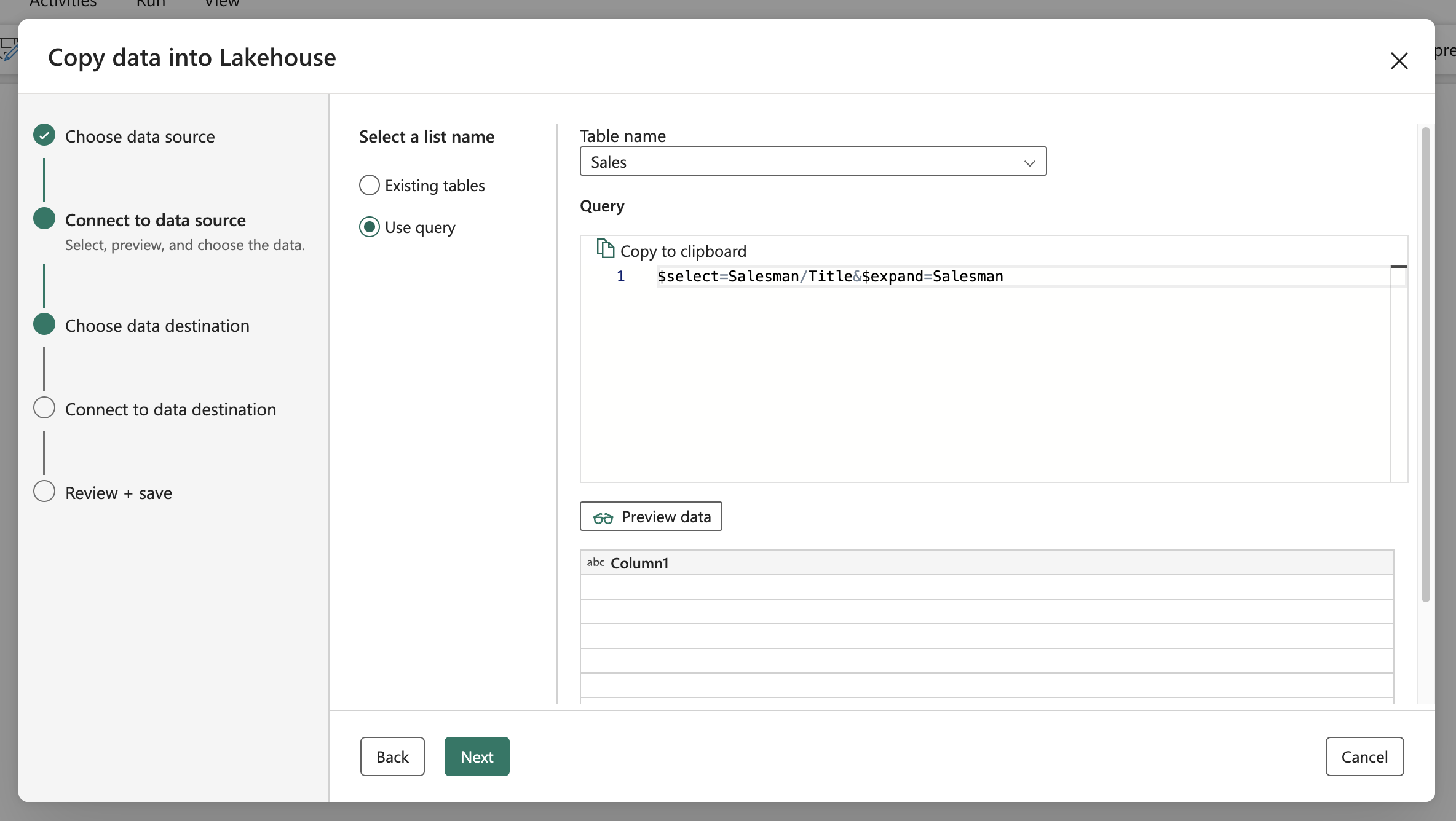 Custom query - $select
Custom query - $select
Because I can’t get all the data for the first time, this option ends here for me. Of course, it is also possible to bring linked tables and join them at the Lakehouse level, but only sometimes. For example, we would not get the internal tables Author, Owner, Creator this way. But to have at least some comparative results regarding capacity usage, I finished loading the data by loading at least IDs in the problem columns into Lakehouse.
 Costs of Copy Activity
Costs of Copy Activity
The measured capacity is excellent. Duration but also CU is relatively low. We’ll see how the rest of the variants turn out.
It’s time for Dataflows….
Dataflows Gen2
Generation one and two differ in various aspects, which we could talk about, but for us, the only option is to use generation two because it can store data in Lakehouse.
Compared to Copy Activity, Dataflow provides many more capabilities, mainly towards data transformation. We would probably get better results if we included the option to write our M code from scratch. But a regular user won’t do that. For that reason, I’m going to stick with no code for this time, follow the example of an average user, and only follow the path I can create with the UI.
The connector for Sharepoint Online sheets is here so that we can use it immediately.
 Dataflow connectors
Dataflow connectors
When setting up this connector, we again fill out a simple window asking us for the address, implementation of the connector, and authentication. As part of the implementation, we have two options - 1.0 (null) and 2.0, when each approaches data acquisition in a slightly different way ~ SharePoint.Tables - PowerQuery M. The consensus is that the 2.0 implementation is faster, so I’ll go with that variant. Most users will also say that newer means better, although this may only sometimes be true.
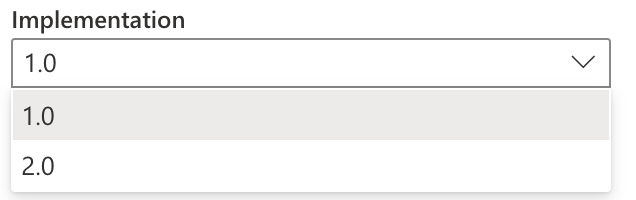 Connector implementations
Connector implementations
Unlike Copy Activity, Dataflows Gen 2 supports authentication via an organizational account, not just the Service Principal (SP). This additional authentication option can be convenient for many developers who don’t have access to SP.
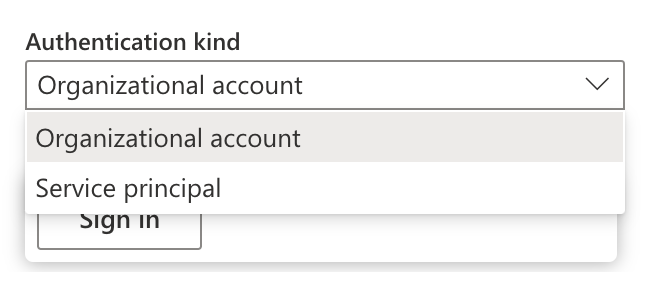 Dataflows Authentication Options
Dataflows Authentication Options
After connecting to the data, there is a classic time for transformations, setting data types, and expanding associated fields that contain values from associated tables due to Lookup columns.
The big difference in Dataflows gen 1 and 2 is the staging option, which creates child Lakehouses for its purposes… Based on an article from Chris Webb - Fabric Dataflows Gen2: To stage or not to stage?, I have disabled staging to make it more performable.
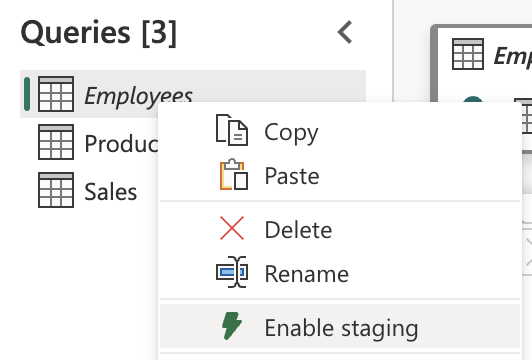 Staging of Queries
Staging of Queries
With dataflow, it is often necessary to measure, in addition to the performance of this artifact, the performance of the associated ones. Fortunately, we don’t have to deal with child Stage Lakehouses when staging is turned off. However, since I’m only interested in the workload of the given artifact at the moment, I only looked at its direct effects on capacity. It immediately follows from these that they are higher than in the Copy Activity and very significantly!
 Costs of Dataflows
Costs of Dataflows
So there are two options. But what about the third one?
Notebooks
This is where we end with UI. Notebooks are code-oriented unless I consider the Data Wrangler option.
Therefore, the performance will depend on what we want to solve in the code. Anyway, here we have to solve authorization, pagination (because Sharepoint returns data after a maximum of 5000 records), and other aspects.
I will not discuss here how to do this specifically; you can find out in the article by Adam Hrouda - Import SharePoint data to Fabric, so don’t hesitate to read it.
For context, the data would not be returned directly here either, so the query needs to be expanded to include the previously mentioned $expand and $select.
 Costs of Dataflows
Costs of Dataflows
For completeness, I mention here what the defined scheme looks like, which is necessary if I want to use it in this way, also with joined tables.
 Defined Schema
Defined Schema
 Costs of Notebooks
Costs of Notebooks
The used nootebook solves a lot of things, and even so, its performance is very good. It is significantly better than Dataflows but, at the same time, worse than the first variant via Copy Activity.
Comparison
Which of these options should I use? IT DEPENDS!
If we need to get data from one sheet that contains only its data and not data from associated sheets, then the most straightforward answer is - Copy Activity. If we also need data from the associated sheets, then Notebook, at least for now, until we get support for $expand in Copy Activity. When we don’t have access or the ability to get Service Principal for Sharepoint, then Dataflow is the answer!
| Criteria | Copy Activity | Dataflows gen2 | Notebooks |
|---|---|---|---|
| Fulfilled requests | NO | YES | YES |
| Duration(s) | 180 | 3 151 | 981 |
| CU(s) | 2 160 | 51 127 | 3 926 |
| Lookup Value Support | NOT NOW | YES | YES |
| Require coding skills | NO | NO* | YES |
* But coding it can help you to make it faster.

